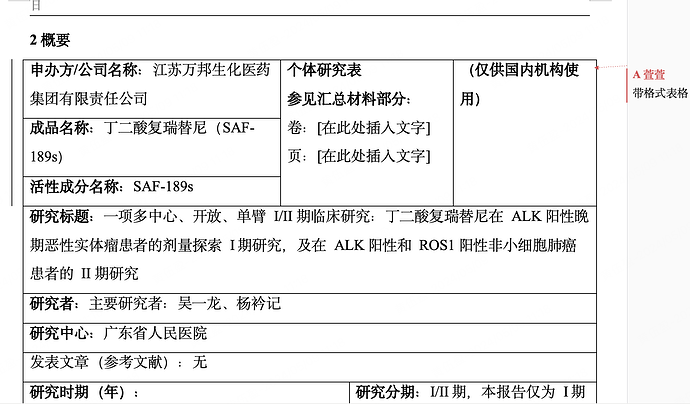
@hhh1111 根据 Microsoft Word 的设计,Microsoft Word 文档中表格的行是完全独立的。这意味着每一行可以有任意数量、任意宽度的单元格。因此,如果您想象第一行有一个宽单元格,第二行有两个窄单元格,那么查看此文档时,第一行的单元格会出现水平合并。但这并不是合并单元格,它只是一个宽单元格。另一种完全正确的情况是第一行有两个单元格。第一个单元格有 CellMerge.First,第二个单元格有 CellMerge.Previous,在这种情况下,它就是一个合并单元格。在这两种情况下,MS Word 中的视觉效果是完全一样的。这两种情况都是有效的。
您可以使用下面的代码,它可以计算出合并单元格跨越了多少列或多少行:
def aw_read_table(self, table, tables):
table_data = []
for row in table.rows:
for cell in row.as_row().cells:
parent_table = table
cell = cell.as_cell()
is_horizontally_merged = cell.cell_format.horizontal_merge != aw.tables.CellMerge.NONE
is_vertically_merged = cell.cell_format.vertical_merge != aw.tables.CellMerge.NONE
table_index = tables.index_of(parent_table)
row_index = parent_table.index_of(row)
cell_index = cell.parent_row.index_of(cell)
row_span = 1
col_span = 1
if row_index < parent_table.rows.count and cell_index < parent_table.rows[row_index].cells.count:
if is_horizontally_merged and is_vertically_merged:
if cell.cell_format.horizontal_merge == aw.tables.CellMerge.FIRST:
for i in range(cell_index, cell.parent_row.cells.count):
if cell.parent_row.cells[i].cell_format.horizontal_merge == aw.tables.CellMerge.PREVIOUS:
col_span += 1
if cell.cell_format.vertical_merge == aw.tables.CellMerge.FIRST:
for i in range(row_index, parent_table.rows.count):
if parent_table.rows[i].cells[cell_index].cell_format.vertical_merge == aw.tables.CellMerge.PREVIOUS:
row_span += 1
elif is_horizontally_merged:
if cell.cell_format.horizontal_merge == aw.tables.CellMerge.FIRST:
for i in range(cell_index, cell.parent_row.cells.count):
if cell.parent_row.cells[i].cell_format.horizontal_merge == aw.tables.CellMerge.PREVIOUS:
col_span += 1
elif is_vertically_merged:
if cell.cell_format.vertical_merge == aw.tables.CellMerge.FIRST:
for i in range(row_index, parent_table.rows.count):
if parent_table.rows[i].cells[cell_index] is not None and \
parent_table.rows[i].cells[
cell_index].cell_format.vertical_merge == aw.tables.CellMerge.PREVIOUS:
row_span += 1
table_data.append({
"type": "tableCell",
"attrs": {
"colspan": col_span,
"rowspan": row_span,
"id": f"{table_index}.{row_index}.{cell_index}",
},
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": cell.get_text(),
}
],
}
],
})
return table_data
doc = aw.Document("CSR.docx")
current_level = 0
data = []
stack = []
for s in doc.sections:
sect = s.as_section()
for node in sect.body.get_child_nodes(aw.NodeType.ANY, False):
if node.node_type == aw.NodeType.PARAGRAPH:
node = node.as_paragraph()
if node.paragraph_format.outline_level in [0, 1, 2, 3, 4, 5]:
level = int(node.paragraph_format.outline_level) + 1
if level > current_level:
# 如果级别更深,将当前标题添加到堆栈
stack.append((current_level, data))
data = []
current_level = level
elif level < current_level:
# 如果级别更浅,将堆栈中的项添加回数据
while stack and stack[-1][0] >= level:
old_level, old_data = stack.pop()
data = old_data + data
current_level = old_level
data.append(
{
"Title": node.get_text(),
"Content": [],
"Level": level,
"Table": [],
"Tbale_name": [],
}
)
else:
if data:
if node.get_text().startswith("表"):
data[-1]["Tbale_name"].append(
node.get_text().strip("SEQ \* ARABIC").strip("SEQ")
)
if (
node.get_text().startswith("表")
or node.get_text().startswith("来源:")
or node.get_text().startswith("图")
):
pass
else:
data[-1]["Content"].append(node.get_text())
if data:
if node.node_type == aw.NodeType.TABLE:
parent_node = node.as_table()
tables = doc.get_child_nodes(aw.NodeType.TABLE, True)
able_content = self.aw_read_table(parent_node, tables)
data[-1]["Table"].append(able_content)
while stack:
old_level, old_data = stack.pop()
data = old_data + data
return data
希望能帮到你。