@akondewar In your code there is no code that removes the the empty region table title row. The same there is not IF field condition in your template the will hide it. So it is expected that the table header remains in the output.
@akondewar You can simply remover tables with a single row. The region in your template occupies the second row, which is removed upon executing mail merge. So you can use code like this to remove a lonely row tables:
for(Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
{
if(t.getRows().getCount()==1)
t.remove();
}
@alexey.noskov
Thanks now table empty rows and table labels removed.
Some types of bullet points are not being correctly converted from word to pdf
here I have attached input word template file and sample source code.
Please provide the sample code
TXN-1266.zip (66.1 KB)
@akondewar To render bullet symbol MS Word as well as Aspose.Words uses Symbol font. It looks like the font is not available in the environment where the document is converted to PDF.
To build an accurate document layout the fonts are required. If Aspose.Words cannot find the fonts used in the document the fonts are substituted . This might lead into the layout and appearance difference. You can implement IWarningCallback to get a notification when font substitution is performed.
The following articles can be useful for you:
https://docs.aspose.com/words/java/specify-truetype-fonts-location/
https://docs.aspose.com/words/java/install-truetype-fonts-on-linux/
Please try either installing or providing the fonts required to render the document. This should resolve the problem.
@alexey.noskov
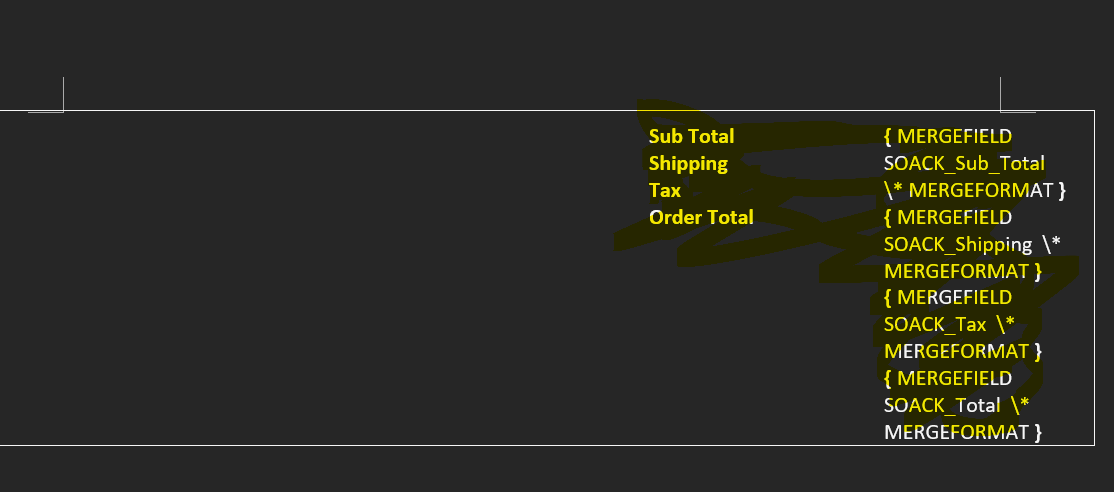
Thanks for the solution, but it’s skip the empty table Label but also not printed next table values.
For example :
SOAckDetails details have data or not it’s skip / not print the 'SOACK_Sub_Total ‘SOACK_Shipping’ etc.
This section data not printed
TestTXN1256.zip (73.7 KB)
@akondewar As I can see fields are properly filled:
Document doc = new Document("C:\\Temp\\in.docx");
String[] names = new String[] {"SOACK_Sub_Total", "SOACK_Shipping", "SOACK_Tax", "SOACK_Total"};
String[] values = new String[] {"Sub_Total", "Shipping", "Tax", "Total"};
doc.getMailMerge().execute(names, values);
doc.save("C:\\Temp\\out.docx");
Hi @alexey.noskov
We are using multiple custom templates, we never know the Mergefeild Table name. So we can not used hardcore MergeField Table name in our code. It is our common code.
Please provide generic solution that will not impact on existing templates.
@akondewar You should make sure the data field names in your data source matches merge field names in your template. The code above just demonstrates that Aspose.Words properly fills the merge fields. So there are no problems with Aspose.Words and it works properly.
Hi @alexey.noskov
Yes Data field names in data source matches merge field name properly.
When I implemented suggested following code that time Some merge field data not printed
SOACK_Sub_Total ‘SOACK_Shipping’ etc.
This happen when any table row have blank then other data not printed after execute t.remove();
for(Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
{
if(t.getRows().getCount()==1)
t.remove();
}
Its Skip the following filed data which is already present in input xml

Please suggest the require code change how to handle this scenario.
@akondewar You can add a condition to check row’s background color. In your case header rows are black:
for (Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
{
if (t.getRows().getCount() == 1 &&
t.getFirstRow().getFirstCell().getCellFormat().getShading().getBackgroundPatternColor().equals(Color.black))
{
t.remove();
}
}
@alexey.noskov
Hi,
Each customer(100+) has their own custom template, and we have multiple custom templates. For all templates, the background color is not black.
requesting you kindly provide generic solution, because this is common code for all customer.
Then how to fix this issue? This is the bug.
Looks like regression of provide solution which is we are implemented.
@akondewar It s not a bug and not a regression. In your template there is a table like this:
| header | header |
|---|---|
| { TableStart }{SomeField} | {SomeField}{ TableEnd } |
After excusing mail merge with data with no records for the region and using MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS only the header row will be left in the template:
DataTable data = new DataTable("Data");
data.getColumns().add("field1");
data.getColumns().add("field2");
Document doc = new Document("C:\\Temp\\in.docx");
doc.getMailMerge().setCleanupOptions(MailMergeCleanupOptions.REMOVE_UNUSED_REGIONS);
doc.getMailMerge().executeWithRegions(data);
doc.save("C:\\Temp\\out.docx");
in.docx (13.2 KB)
out.docx (10.4 KB)
This is an expected behavior since the region occupies only the second row of the table. You can try left the not used regions as is and then remove whole table that contains it, but still this is not general solution and all depends on your templates:
DataTable data = new DataTable("Data");
data.getColumns().add("field1");
data.getColumns().add("field2");
Document doc = new Document("C:\\Temp\\in.docx");
doc.getMailMerge().executeWithRegions(data);
// Removed tables with unused regions.
for (Field f : doc.getRange().getFields())
{
if (f.getType() == FieldType.FIELD_MERGE_FIELD)
{
FieldMergeField mf = (FieldMergeField)f;
if (mf.getFieldName().toLowerCase().startsWith("tablestart"))
{
Node parentTable = mf.getStart().getAncestor(NodeType.TABLE);
if (parentTable != null && parentTable.getParentNode() != null)
parentTable.remove();
}
}
}
doc.save("C:\\Temp\\out.docx");
As mentioned the solution is not general because your data can contain empty data:
DataTable data = new DataTable("Data");
data.getColumns().add("field1");
data.getColumns().add("field2");
data.getRows().add("", "");
In this case the region is used and the above code will not work and in the result document there will be a table with header and one empty row:
out.docx (10.5 KB)
You can partially resolve the problem by using MailMergeCleanupOptions.REMOVE_EMPTY_TABLE_ROWS, in this case there will be only the heater row left in the output:
out.docx (10.4 KB)
So there must be some marker that will allow to detect the table headers and check whether there are data in the table. For example, you can use RowFormat.HeadingFormat property for this, but again this will require the appropriate setup in all your templates.
Although it’s an expected behavior for Aspose now, for us (and our impacted customers) this is an altered behavior after upgrading to newer version. And I must tell you that, in a report, nobody wants to see a table with just the HEADERS and no data, for any practical purposes.
This altered behavior is not acceptable to us as an existing customer, with no handle to deal with it ONLY at code level (because changing 100s of templates at 100+ customers is out of question as a part of workaround).
Will Aspose be able to work on providing additional CleanupOptions, to clear such EMPTY HEADERS? We want to have a cleaner solution to this problem, even if it means a little bit of wait time.
@akondewar
We have opened the following new ticket(s) in our internal issue tracking system and will deliver their fixes according to the terms mentioned in Free Support Policies.
Issue ID(s): WORDSNET-27525
You can obtain Paid Support Services if you need support on a priority basis, along with the direct access to our Paid Support management team.
Thanks, Alexey. I will create a paid support ticket to see if this can be prioritized. Thank you!
1 Like
@gbrunda The issue priority has been raised. We will keep you updated and let you know once it is resolved or we have more information for you.
The issues you have found earlier (filed as WORDSNET-27525) have been fixed in this Aspose.Words for Java 24.12 update.