@Tiaohh 你是说查看你最近写的帖子?
你好我写的这个不对 怎么把表格插入段落内容下面呢 我写的不对 是需要插入标题段落后面
def find_last_related_paragraph(paragraphs, title_text):
"""
找到标题后的最后一个相关段落。
"""
title_paragraph = None
# 找到目标标题
for para in paragraphs:
para = para.as_paragraph()
print(f"当前段落: '{para.get_text().strip()}',标题: '{title_text}'")
if para.get_text().strip() == title_text:
title_paragraph = para
break
if title_paragraph is None:
raise ValueError(f"未找到标题: {title_text}")
# 找到标题后的最后一个相关段落
last_related_paragraph = title_paragraph
# 检查是否存在下一个节点,且其 outline_level 大于标题
while (
last_related_paragraph.next_sibling
and last_related_paragraph.next_sibling.as_paragraph().paragraph_format.outline_level
> title_paragraph.paragraph_format.outline_level
):
last_related_paragraph = last_related_paragraph.next_sibling
return last_related_paragraph
async def generate_docx_with_result_laikai(
header_list: list,
table_list: list,
save_path,
template_path,
):
logger.info(f"header list内容: {header_list}")
logger.info(f"table list内容: {table_list}")
base_file = template_path
clear_save_path = base_file
doc_main = aw.Document(clear_save_path)
paragraphs = doc_main.get_child_nodes(aw.NodeType.PARAGRAPH, True)
for para in paragraphs:
para = para.as_paragraph()
para_content = para.to_string(aw.SaveFormat.TEXT)
para_content = para_content.replace("\r", "")
para_content = (
para_content.strip()
) # 特殊地方,发现目录中有这个符号,暂时不知道符号是干啥的
print(para_content, header_list)
if (
para_content in header_list or para_content.capitalize() in header_list
): # 如果当前段落中有写作内容,那么找到内容,找到生成的结果
table_header = aw.Paragraph(doc_main)
table_header.paragraph_format.style_identifier = aw.StyleIdentifier.NORMAL
table_header.paragraph_format.alignment = aw.ParagraphAlignment.CENTER
para = find_last_related_paragraph(paragraphs, para_content)
run = aw.Run(doc_main, "")
# 将文本设置为加粗
run.font.bold = True
# 将加粗的 Run 对象添加到表头段落中
table_header.append_child(run)
# 增加一步 现将当前para段落中的内容清空
# para.parent_node.insert_after(table_header, para)
try:
if para_content in ["APPENDICES", "REFERENCES"]:
para_content = para_content.capitalize()
idx_num = header_list.index(para_content)
# 获取header对应的table
num_tables = len(table_list[idx_num][::-1])
logger.info(f"当前表格长度:{num_tables}")
for _index, info in enumerate(table_list[idx_num]):
table_id = info.get("id", "")
is_header_and_footer = info.get("is_header_and_footer", "")
logger.warning(f"table_id in table list:{table_id}")
aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.rtf")
).save(os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx"))
# 判断是否需要页眉页脚 False为删除页眉页脚
if not is_header_and_footer:
document = Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
for section in document.sections:
section.footer.is_linked_to_previous = True
section.header.is_linked_to_previous = True
document.save(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
doc_rtf = aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
builder = aw.DocumentBuilder(doc_rtf)
# 判断分页是否续表
builder.row_format.heading_format = False
# builder.row_format.heading_format = True
doc_rtf.save(os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx"))
_doc = aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
_tables = _doc.get_child_nodes(aw.NodeType.TABLE, True)
_tables = [t for t in _tables]
for table in _tables[::-1]:
if table.get_ancestor(aw.NodeType.BODY):
i = _tables.index(table)
temp = _tables[i]
_tables[i] = _tables[i - 1]
_tables[i - 1] = temp
# 删除表格第一行内容
logger.info(f"插入表格: {table_id}")
for table in _tables[
::-1
]: # 将table 信息反向的插入到word文件中。TODO 表格美化
table_clone = table.as_table().clone(True)
imported_table = doc_main.import_node(table_clone, True)
logger.info(
f"imported table 节点类型: {imported_table.node_type}"
)
if imported_table.node_type == aw.NodeType.TABLE:
logger.info(f"imported table 节点是表格")
imported_table = imported_table.as_table()
imported_table.preferred_width = (
aw.tables.PreferredWidth.from_percent(100)
)
for index, row in enumerate(imported_table.rows):
row = row.as_row()
# print(index, row.get_text().strip())
for cell_index, cell in enumerate(row.cells):
cell = cell.as_cell()
cell.cell_format.vertical_alignment = (
aw.tables.CellVerticalAlignment.BOTTOM
)
for paragraph in cell.paragraphs:
paragraph = paragraph.as_paragraph()
# 居中对齐
for run in paragraph.runs:
run = run.as_run()
run.font.name = (
"Courier New" # 设置西文是新罗马字体
)
run.font.name_far_east = "宋体"
run.font.size = 8
print("一个表格s数据")
# 在插入段落标题之后插入段落内容
para.parent_node.insert_after(imported_table, para)
# table_newline = aw.Paragraph(doc_main)
# run = aw.Run(doc_main, "")
# table_newline.append_child(run)
# imported_table.parent_node.insert_after(
# table_newline, imported_table
# )
else:
logger.info(f"当前段落不需要插入表格内容")
# 插入result 模型输出结果 结果只插入一次,table插入完成后插入
# TODO 段落美化
except:
logger.warning(f"没有找到header{traceback.format_exc()}")
print("没有找到header", traceback.format_exc())
doc_main.save(save_path)
return {"prompt_tokens": 1, "complete_tokens": 1, "total_tokens": 1}代码
存储的文件id信息。然后读取文件
)
builder = aw.DocumentBuilder(doc_rtf)
# 判断分页是否续表
builder.row_format.heading_format = False
# builder.row_format.heading_format = True
doc_rtf.save(os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx"))
_doc = aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
_tables = _doc.get_child_nodes(aw.NodeType.TABLE, True)
_tables = [t for t in _tables]
for table in _tables[::-1]:
if table.get_ancestor(aw.NodeType.BODY):
i = _tables.index(table)
temp = _tables[i]
_tables[i] = _tables[i - 1]
_tables[i - 1] = temp
# 删除表格第一行内容
logger.info(f"插入表格: {table_id}")
for table in _tables[
::-1
]: # 将table 信息反向的插入到word文件中。TODO 表格美化
table_clone = table.as_table().clone(True)
imported_table = doc_main.import_node(table_clone, True)
logger.info(
f"imported table 节点类型: {imported_table.node_type}"
)
for table in _tables[::-1]:
if table.get_ancestor(aw.NodeType.BODY):
i = _tables.index(table)
temp = _tables[i]
_tables[i] = _tables[i - 1]
_tables[i - 1] = temp怎么把这个内容合成一个表格信息呢。,页眉正文表格页脚。合并成一个表格信息呢
@Tiaohh 您可以复制现有行、更新数据,并使用 "insert_before "或 "append_child "在顶部或底部插入数据。
row_to_insert = new_imported_table.first_row.clone(True).as_row()
row_to_insert.cells[0].first_paragraph.append_child(aw.Run(dst_doc, "This is new run!"))
new_imported_table.insert_before(row_to_insert, new_imported_table.first_row)
@Tiaohh 我稍微修改了一下你的代码,就能得到你想要的结果:
@staticmethod
def find_last_related_paragraph(para):
last_related_paragraph = para
while (
last_related_paragraph.next_sibling
and last_related_paragraph.next_sibling.as_paragraph().paragraph_format.outline_level
> para.paragraph_format.outline_level
):
last_related_paragraph = last_related_paragraph.next_sibling
return last_related_paragraph
para = self.find_last_related_paragraph(para)
for table in _tables[::-1]:
if table.get_ancestor(aw.NodeType.BODY):
i = _tables.index(table)
temp = _tables[i]
_tables[i] = _tables[i - 1]
_tables[i - 1] = temp怎么把这个内容合成一个表格信息呢。,页眉正文表格页脚。合并成一个表格信息呢 就是目前这里是3个表格,我想要合并成一个表格里面
如果我做编辑器功能,文档解析出来的格式 还有保存到文档的格式数据格式怎么处理比较方便呢
@Tiaohh 因为表格在中间,所以你可以找到第一个表格,然后查看前一行,获得标题文本。使用此代码可在表格顶部添加页眉:
row_to_insert = new_imported_table.first_row.clone(True).as_row()
for cell in row_to_insert.cells:
cell = cell.as_cell()
cell.first_paragraph.runs.clear()
row_to_insert.cells[0].first_paragraph.append_child(aw.Run(dst_doc, "Header text"))
new_imported_table.insert_before(row_to_insert, new_imported_table.first_row)
然后获取页脚文本,像这样使用代码:
row_to_insert = new_imported_table.last_row.clone(True).as_row()
for cell in row_to_insert.cells:
cell = cell.as_cell()
cell.first_paragraph.runs.clear()
row_to_insert.cells[0].first_paragraph.append_child(aw.Run(dst_doc, "Footer text"))
new_imported_table.append_child(row_to_insert)
对所有表格都这样做,然后在第一个表格中使用 append_child 将它们合并。
@Tiaohh 在行格式中保留新文本的唯一方法是复制 “运行节点”,清除行中的所有文本,然后添加克隆行:
row_to_insert = new_imported_table.first_row.clone(True).as_row()
cloned_run = row_to_insert.cells[0].as_cell().first_paragraph.runs[0].as_run().clone(True)
cloned_run.as_run().text = "New text"
for cell in row_to_insert.cells:
cell = cell.as_cell()
cell.remove_all_children()
cell.ensure_minimum()
row_to_insert.cells[0].as_cell().first_paragraph.runs.add(cloned_run)
好的谢谢我看下。
以下是rtf表格写入docx问题,续表问题,如果rtf表格写到docx里吗分页之后进行续表,续表的内容为 表格的第二行数据 我把rtf表格转换成docx 您可以帮我看下吗
t_ae_1(1).docx (20.9 KB)
就是我需要有续表功能,写进去内容呈现的样式是我发的效果图那种
写入到docx里吗 如果分页之后,需要有续表的功能

目前写入的表格样式
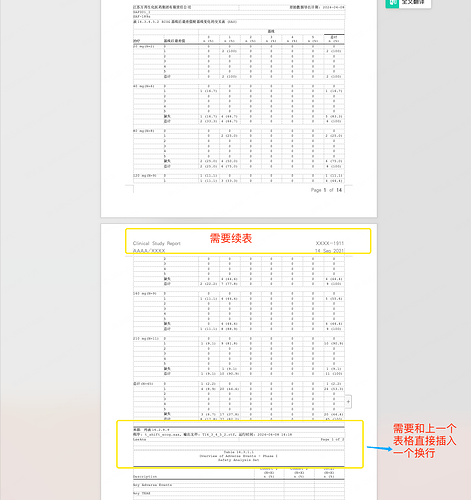
我希望的样式 已经在截图中标记了
以下是代码
async def generate_docx_with_result_laikai(
header_list: list,
table_list: list,
save_path,
template_path,
):
logger.info(f"header list内容: {header_list}")
logger.info(f"table list内容: {table_list}")
base_file = template_path
clear_save_path = base_file
doc_main = aw.Document(clear_save_path)
paragraphs = doc_main.get_child_nodes(aw.NodeType.PARAGRAPH, True)
for para in paragraphs:
para = para.as_paragraph()
para_content = para.to_string(aw.SaveFormat.TEXT)
para_content = para_content.replace("\r", "")
para_content = (
para_content.strip()
) # 特殊地方,发现目录中有这个符号,暂时不知道符号是干啥的
if (
para_content in header_list or para_content.capitalize() in header_list
): # 如果当前段落中有写作内容,那么找到内容,找到生成的结果
table_header = aw.Paragraph(doc_main)
table_header.paragraph_format.style_identifier = aw.StyleIdentifier.NORMAL
table_header.paragraph_format.alignment = aw.ParagraphAlignment.CENTER
para = find_last_related_paragraph(paragraphs, para_content)
# run = aw.Run(doc_main, "")
# # 将文本设置为加粗
# run.font.bold = True
# # 将加粗的 Run 对象添加到表头段落中
# table_header.append_child(run)
# # 增加一步 现将当前para段落中的内容清空
# para.parent_node.insert_after(table_header, para)
try:
if para_content in ["APPENDICES", "REFERENCES"]:
para_content = para_content.capitalize()
idx_num = header_list.index(para_content)
# 获取header对应的table
num_tables = len(table_list[idx_num])
logger.info(f"当前表格长度:{num_tables}")
for _index, info in enumerate(table_list[idx_num]):
table_id = info.get("id", "")
is_header_and_footer = info.get("is_header_and_footer", "")
# logger.warning(f"table_id in table list:{table_id}")
aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.rtf")
).save(os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx"))
# 判断是否需要页眉页脚 False为删除页眉页脚
if not is_header_and_footer:
document = Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
for section in document.sections:
section.footer.is_linked_to_previous = True
section.header.is_linked_to_previous = True
document.save(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
doc_rtf = aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
# builder = aw.DocumentBuilder(doc_rtf)
# # 判断分页是否续表
# # builder.row_format.heading_format = False
# builder.row_format.heading_format = True
doc_rtf.save(os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx"))
_doc = aw.Document(
os.path.join(settings.UPLOAD_PATH, f"{table_id}.docx")
)
_tables = _doc.get_child_nodes(aw.NodeType.TABLE, True)
_tables = [t for t in _tables]
for table in _tables[::-1]:
if table.get_ancestor(aw.NodeType.BODY):
i = _tables.index(table)
temp = _tables[i]
_tables[i] = _tables[i - 1]
_tables[i - 1] = temp
# 删除表格第一行内容
logger.info(f"插入表格: {table_id}")
for table in _tables[
::-1
]: # 将table 信息反向的插入到word文件中。TODO 表格美化
table_clone = table.as_table().clone(True)
imported_table = doc_main.import_node(table_clone, True)
logger.info(
f"imported table 节点类型: {imported_table.node_type}"
)
if imported_table.node_type == aw.NodeType.TABLE:
logger.info(f"imported table 节点是表格")
imported_table = imported_table.as_table()
imported_table.preferred_width = (
aw.tables.PreferredWidth.from_percent(100)
)
for index, row in enumerate(imported_table.rows):
row = row.as_row()
# print(index, row.get_text().strip())
for cell_index, cell in enumerate(row.cells):
cell = cell.as_cell()
cell.cell_format.vertical_alignment = (
aw.tables.CellVerticalAlignment.BOTTOM
)
for paragraph in cell.paragraphs:
paragraph = paragraph.as_paragraph()
# 居中对齐
for run in paragraph.runs:
run = run.as_run()
run.font.name = (
"Courier New" # 设置西文是新罗马字体
)
run.font.name_far_east = "宋体"
run.font.size = 8
print("一个表格s数据")
run = aw.Run(doc_main, "")
# 将文本设置为加粗
run.font.bold = True
# 将加粗的 Run 对象添加到表头段落中
table_header.append_child(run)
# 增加一步 现将当前para段落中的内容清空
para.parent_node.insert_after(table_header, para)
# 在插入段落标题之后插入段落内容
# para.parent_node.insert_after(imported_table, para)
table_header.parent_node.insert_after(
imported_table, table_header
)
# table_newline = aw.Paragraph(doc_main)
# run = aw.Run(doc_main, "")
# table_newline.append_child(run)
# imported_table.parent_node.insert_after(
# table_newline, imported_table
# )
else:
logger.info(f"当前段落不需要插入表格内容")
# 插入result 模型输出结果 结果只插入一次,table插入完成后插入
# TODO 段落美化
except:
logger.warning(f"没有找到header{traceback.format_exc()}")
print("没有找到header", traceback.format_exc())
doc_main.save(save_path)
return {"prompt_tokens": 1, "complete_tokens": 1, "total_tokens": 1}