Hi Team,
How i can set bullets and numering and left indent to current node by getting all the styles from parent node.
Can you please give me some sample code for this.
Currently i am using logic like
Paragraph para = (Paragrapgh) currentNode.getParentNode();
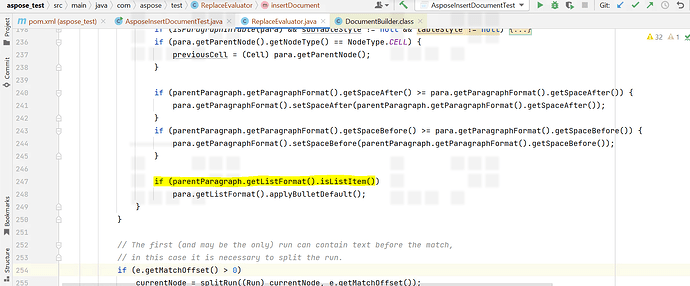
if(para.getListFormat().isListItem()){
childPara.getListFormat().applyBulletDefault();
}
So with above code where ever numbering is there there also by default bullets are setting. Can u plz give some sample code to set bullets and numbers and indent.
We are using aspose words for java 24.4 version
Thanks,
Priyanka.
@priyanka9 Could you please attach your input, current and expected output documents here for our refence? This will help us to better understand your requirements and provide you a solution.
Hi @alexey.noskov ,
Plz find the few inputs before replacing and after replacing how document look like.
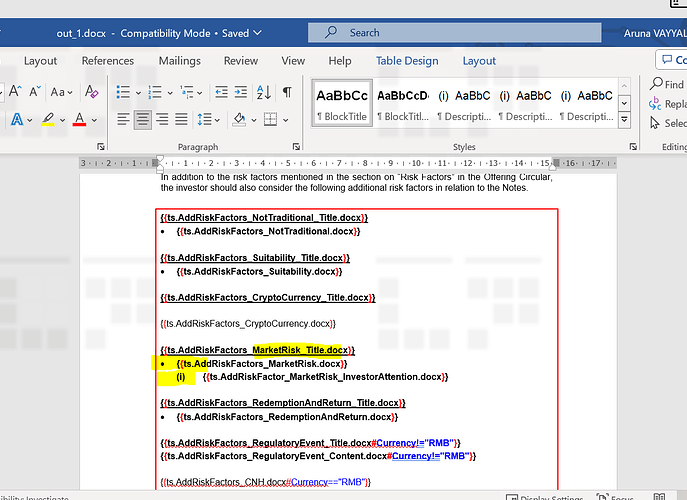
Base doc before replace :
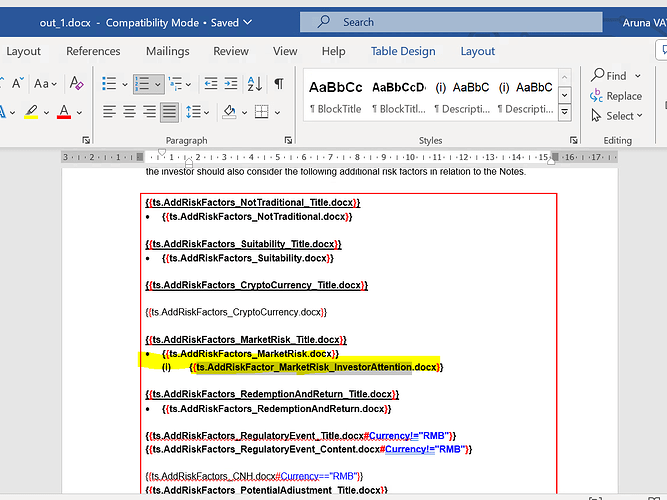
After replacing :
Note : According to our current code by default we are applying bullet but we need to check what is the type of listItem and if it is a bullet need to apply bullet with indent and or if it is a number need to apply number.
Can you plz provide me some sample code since we are new to this not sure how to start.
Thanks,
Priyanka.
@priyanka9 Could you please attach your simplified input (with one placeholder) and sample code that will allow us to reproduce the problem? Unfortunately, screenshots does not allow to analyze the problem. We will check the issue and provide you more information.
Hi @alexey.noskov ,
I have created sample project for u by replacing listItem expressions alone.
Sample project :
aspose_test.zip (391.7 KB)
Input files if incase they are missing in project :
out_1.docx (34.8 KB)
ts.AddRiskFactors_MarketRisk (1).docx (18.6 KB)
ts.AddRiskFactors_MarketRisk_Title.docx (18.2 KB)
ts.AddRiskFactor_MarketRisk_InvestorAttention (1).docx (18.1 KB)
Plz consider below section alone in the document since i didnt replace whole docuemnt.
After replacing :
Thanks,
Priyanka.
@priyanka9 Unfortunately, it is still not clear what the problem is. Could you please attach your simplified input (with one placeholder) and simplified code that will allow us to reproduce the problem? Also, in another your thread we have suggested a simpler way to replace placeholders with documents. Why did not you follow the suggestion, and still uses the old approach?
Hi @alexey.noskov ,
The problem is we are not able to insert numbers in generated document and we need that code like how to check whether ListItem is a bullet one or number one and how to replace in document ?
R u not able to run the sample project ?
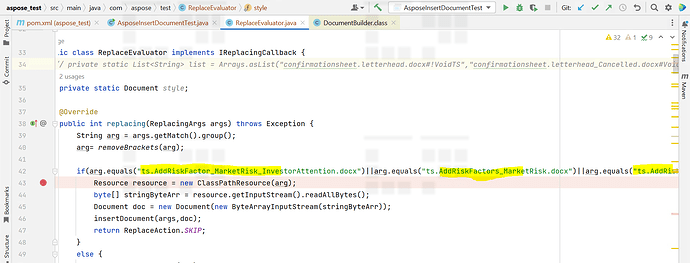
I created sample project by reproducing the same problem by replacing the arguments which are having listItems.did u gone through my code which is there inside insertDocument for listItem how we are handling?
To simplify input only I highlighted exact arguments which are having both bullet and number formats and i can not remove remaining stuff from doc as it will cause some style issues . Plz check this below code and also u can find expected and actual behaviour in above screenshots.
Note : We can not change the suggested approach for replacing immidiately as existing code is already there in production. It will take some time.
Let me know if u need any other inputs we need to close this item very urgently plz help on this urgently.
Thanks,
Priyanka.
@priyanka9 As I can see your template already has list formatting applied to the appropriate placeholder paragraphs. So I do not see a need to detect type of the list applied to the paragraph. You should simply use the formatting of the target paragraph when insert the source document’s content. I have simplified your template to the following:
in.docx (18.3 KB)
Here is simplified code that handles list items:
Document baseAsposeDocument = new Document("C:\\Temp\\in.docx");
String regex = "\\{\\{([^}]*)\\}\\}";
Pattern pattern = Pattern.compile(regex);
FindReplaceOptions options = new FindReplaceOptions();
options.setDirection(FindReplaceDirection.FORWARD);
options.setReplacingCallback(new ReplaceEvaluator());
baseAsposeDocument.getRange().replace(pattern, "", options);
baseAsposeDocument.save("C:\\Temp\\out.docx", SaveFormat.DOCX);
public class ReplaceEvaluator implements IReplacingCallback {
@Override
public int replacing(ReplacingArgs args) throws Exception {
String arg = removeBrackets(args.getMatch().group());
if (arg.equals("ts.AddRiskFactor_MarketRisk_InvestorAttention.docx") || arg.equals("ts.AddRiskFactors_MarketRisk.docx") || arg.equals("ts.AddRiskFactors_MarketRisk_Title.docx")) {
Document srcDocument = new Document("C:\\Temp\\" + arg);
Document dstDocument = (Document) args.getMatchNode().getDocument();
NodeImporter importer = new NodeImporter(srcDocument, dstDocument, ImportFormatMode.USE_DESTINATION_STYLES);
DocumentBuilder builder = new DocumentBuilder(dstDocument);
// Get placeholders runs.
ArrayList<Run> runs = getMatchedRuns(args);
// Move to the last Run
builder.moveTo(runs.get(runs.size() - 1));
if (builder.getCurrentParagraph().isListItem()) {
// If the current paragraph is list items
// insert the source document paragraphs content as list items.
for (Paragraph p : srcDocument.getFirstSection().getBody().getParagraphs()) {
Paragraph dstPara = (Paragraph) importer.importNode(p, true);
while (dstPara.hasChildNodes())
builder.insertNode(dstPara.getFirstChild());
builder.writeln();
}
// Remove last empty paragraph.
builder.getCurrentParagraph().remove();
} else {
builder.insertDocumentInline(srcDocument, ImportFormatMode.USE_DESTINATION_STYLES, new ImportFormatOptions());
}
// Remove placeholder.
for (Run r : runs)
r.remove();
return ReplaceAction.SKIP;
} else {
args.setReplacement(arg);
return ReplaceAction.REPLACE;
// return setReplacementWhenConditionFalse(args);
}
}
protected static ArrayList<Run> getMatchedRuns(ReplacingArgs args) {
// This is a Run node that contains either the beginning or the complete match.
Node currentNode = args.getMatchNode();
// The first (and may be the only) run can contain text before the match,
// in this case it is necessary to split the run.
if (args.getMatchOffset() > 0)
currentNode = splitRun((Run) currentNode, args.getMatchOffset());
// This array is used to store all nodes of the match for further deleting.
ArrayList<Run> runs = new ArrayList<Run>();
// Find all runs that contain parts of the match string.
int remainingLength = args.getMatch().group().length();
while (
remainingLength > 0 &&
currentNode != null &&
currentNode.getText().length() <= remainingLength) {
runs.add((Run) currentNode);
remainingLength -= currentNode.getText().length();
// Select the next Run node.
// Have to loop because there could be other nodes such as BookmarkStart etc.
do {
currentNode = currentNode.getNextSibling();
} while (currentNode != null && currentNode.getNodeType() != NodeType.RUN);
}
// Split the last run that contains the match if there is any text left.
if (currentNode != null && remainingLength > 0) {
splitRun((Run) currentNode, remainingLength);
runs.add((Run) currentNode);
}
return runs;
}
private static Run splitRun(Run run, int position) {
Run afterRun = (Run) run.deepClone(true);
run.getParentNode().insertAfter(afterRun, run);
afterRun.setText(run.getText().substring(position));
run.setText(run.getText().substring(0, position));
return afterRun;
}
public static String removeBrackets(String input) {
// Define a regex pattern to match {{...}} and use a Matcher to find and replace
Pattern pattern = Pattern.compile("\\(\\{\\{(.*?)\\}\\}\\)|\\{\\{(.*?)\\}\\}");
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
if (matcher.group(1) != null) {
String match = matcher.group(1);// Get the content within {{}}
String replaced = match.replaceAll("\\[|\\]", "");
return replaced;
} else if (matcher.group(2) != null) {
String match = matcher.group(2);// Get the content within {{}}
String replaced = match.replaceAll("\\[|\\]", "");
return replaced;
}
}
return input;
}
}
And here is the produced output: out.docx (18.4 KB)
Which is, I suppose, your expected output document.
Hi Alex,
I have replaced your solution in our code it worked as expected but it is braking other styles so i reverted your solution. I will comeback this on later if you need sample project and outcome we received with this fix.
If possible can you please give some fix which can fit to our current approach.
Thanks,
Priyanka.
@priyanka9 I am afraid there is no silver bullet solution and you are in the better position to debug and modify your solution fit your needs. We can only provide you a basic approach, which you are free to modify for your needs.