我在尝试识别word中某个table中每一个row的layoutCollector.getEndPageIndex,但是发现这个函数经常会识别错误。我会把样例发给你。
代码如下:
package com.crane.wordformat;
import com.aspose.words.*;
public class testFormat {
public static void main(String[] args) throws Exception {
License license = new License();
license.setLicense("C:\\\\Users\\\\11964\\\\Desktop\\\\Aspose.Words.Java.lic");
Document doc = new Document("C:\\Users\\11964\\Desktop\\test_table.docx");
Node[] nodeArray = doc.getChildNodes(NodeType.ANY,true).toArray();
// 获取table和表题的对应关系
LayoutCollector layoutCollector = new LayoutCollector(doc);
for (int index = 0 ; index < nodeArray.length; index ++) {
Node node = nodeArray[index];
if (node instanceof Table table) {
Row[] rows = table.getRows().toArray();
int endPageIndex = layoutCollector.getEndPageIndex(rows[0]);
for (Row row: table.getRows()) {
int rowIndex = layoutCollector.getEndPageIndex(row);
if (endPageIndex != rowIndex) {
System.out.println("table:"+rows[0].getText());
System.out.println(row.getText());
System.out.println();
break;
}
}
}
}
doc.save("C:\\\\Users\\\\11964\\\\Desktop\\\\output.docx");
}
}
word文件为:
test_table.docx (89.1 KB)
请您帮忙看一下输出,谢谢。
@qhkyqhfe 我简化了你的代码:
LoadOptions loadOptions = new LoadOptions();
loadOptions.getLanguagePreferences().setDefaultEditingLanguage(EditingLanguage.CHINESE_PRC);
Document doc = new Document("test_table.docx");
NodeCollection tables = doc.getChildNodes(NodeType.TABLE, true);
LayoutCollector layoutCollector = new LayoutCollector(doc);
for (Table table : (Iterable<Table>) tables) {
for (Row row : table.getRows()) {
int rowIndex = layoutCollector.getEndPageIndex(row);
System.out.println("table: " + row.getText());
System.out.println(" Row index: " + rowIndex);
System.out.println();
}
}
doc.save("output.pdf");
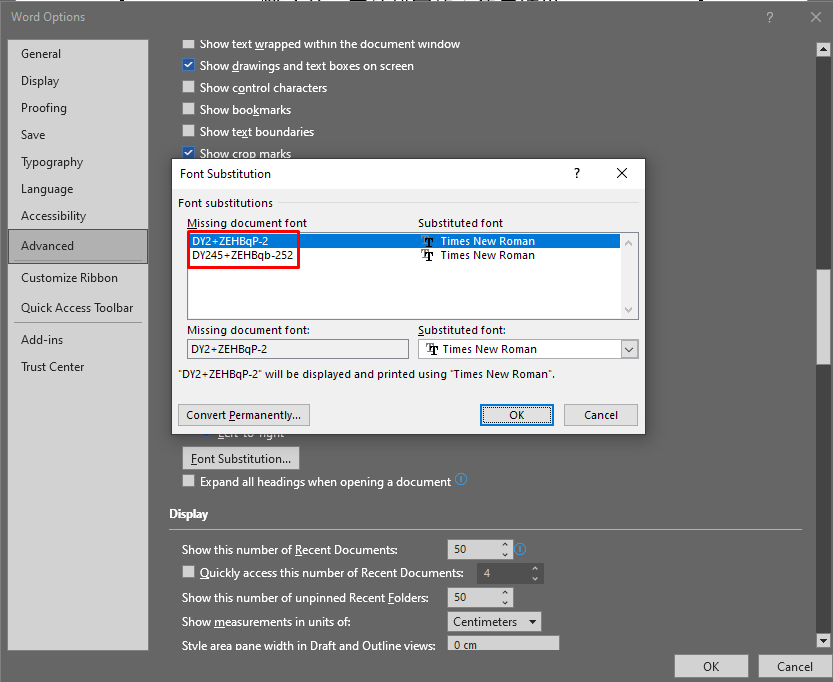
我发现 pdf 文件中的内容与 MS Word 中的内容不一样。这就是为什么使用 getEndPageIndex 时会出现这种情况。我的 WarningCallback 没有抛出任何错误,但我在文档中看到了遗漏的字体。
DY2+ZEHBQP-2
DY245+ZEHBqb-252
如果您有这种字体,能否与我们分享?另外,请尝试将您的文档转换为 pdf 格式,并将结果与 .docx 文件进行比较。
output.pdf (306.2 KB)
我的输出的pdf格式和程序的输出的页码完全相同,但是和word的页码不同。我不知道什么因素导致的。
请问pdf渲染引擎和word渲染引擎有什么区别吗?会导致这样的内容不同的原因
这两种字体我都在网上找不到。请问有没有什么方法可以找到使用 这些缺失字体的内容。我可以手动替换一下字体。这样可以判断是否是因为字体的原因导致的排版错乱
@qhkyqhfe 我检查了文件,通过使用以下代码设置兼容性选项,可以在 PDF 和 DOCX 之间获得正确的结果:
LoadOptions loadOptions = new LoadOptions();
loadOptions.getLanguagePreferences().setDefaultEditingLanguage(EditingLanguage.CHINESE_PRC);
Document doc = new Document("test_table.docx", loadOptions);
doc.getCompatibilityOptions().optimizeFor(MsWordVersion.WORD_2016);
NodeCollection tables = doc.getChildNodes(NodeType.TABLE, true);
LayoutCollector layoutCollector = new LayoutCollector(doc);
for (Table table : (Iterable<Table>) tables) {
for (Row row : table.getRows()) {
int rowIndex = layoutCollector.getEndPageIndex(row);
System.out.println("table: " + row.getText());
System.out.println(" Row index: " + rowIndex);
System.out.println();
}
}
doc.save("output.pdf");
你能检查一下你那边吗?
以下是我的输出结果:
package com.crane.wordformat;
import com.aspose.words.*;
public class testFormat {
public static void main(String[] args) throws Exception {
License license = new License();
license.setLicense("C:\\\\Users\\\\11964\\\\Desktop\\\\Aspose.Words.Java.lic");
LoadOptions loadOptions = new LoadOptions();
loadOptions.getLanguagePreferences().setDefaultEditingLanguage(EditingLanguage.CHINESE_PRC);
Document doc = new Document("C:\\Users\\11964\\Desktop\\test_table.docx",loadOptions);
doc.getCompatibilityOptions().optimizeFor(MsWordVersion.WORD_2016);
NodeCollection tables = doc.getChildNodes(NodeType.TABLE, true);
LayoutCollector layoutCollector = new LayoutCollector(doc);
for (Table table : (Iterable<Table>) tables) {
for (Row row : table.getRows()) {
int rowIndex = layoutCollector.getEndPageIndex(row);
System.out.println("table: " + row.getText());
System.out.println(" Row index: " + rowIndex);
System.out.println();
}
}
doc.save("C:\\\\Users\\\\11964\\\\Desktop\\\\output.pdf");
doc.save("C:\\\\Users\\\\11964\\\\Desktop\\\\output.docx");
}
}
这是我的输出:
output.pdf (306.1 KB)
依然是错误的
plus:我还尝试了将WORD_2016替换成了WORD_2019,WORD_2013等。都是一样的
@qhkyqhfe 能否请您检查一下 24.6 型号的结果?
@qhkyqhfe 我的 24.5 型有这个问题,但 24.6 型没有。