在使用aspose.word 读取一段文档内容时,
代码如下:
//获取当前文档中所有的field_start,遍历这个集合.
NodeCollection<FieldStart> childNodes = document.getChildNodes(NodeType.FIELD_START,true);
循环这个集合,在使用childNode.getField().unlink();
然后使用aspose.word 获取table里面的paragarpg的所有子级在获取run的内容.
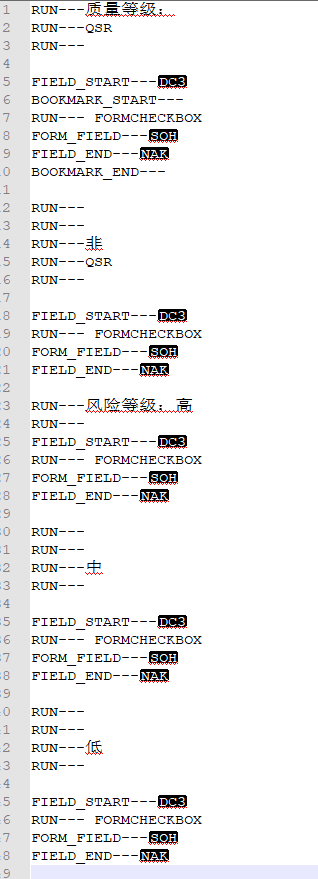
通过上面的方法获取正常结构下的field内容是正常的.但是现在解析的文档内容field结构是缺失的.
正常的field结构:
FieldStart
FieldSeparator
FieldEnd
缺失的field结构
FieldStart
FieldEnd
这种缺失的结构导致读取的run的时候多出了内容"FORMCHECKBOX".
下面是结构截图和文档截图.开发环境问题 没办法上传原始文档.
paragraph的子级结构截图:
原始文档截图如下:

望解答,谢谢!