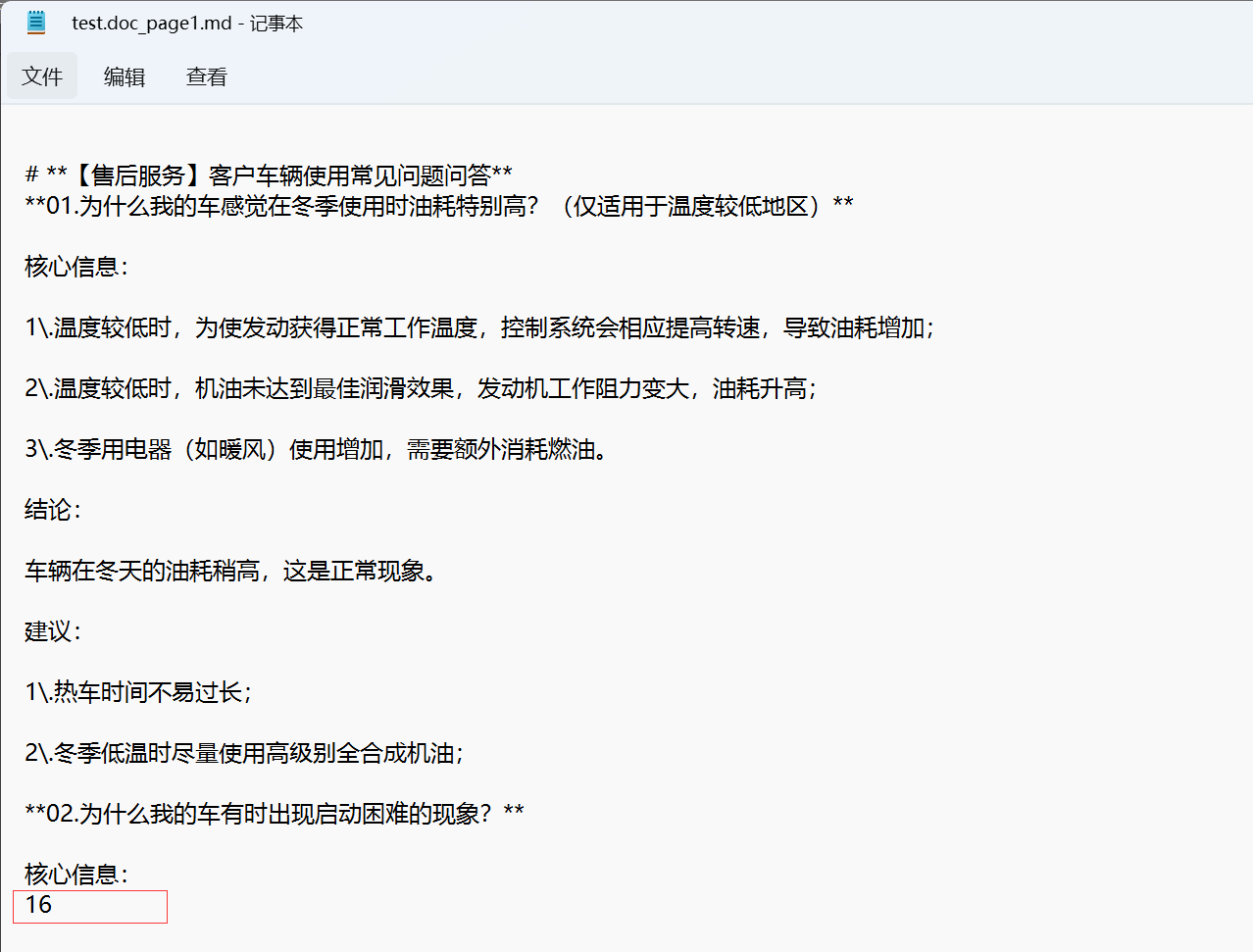
使用aspose.word按页码拆分doc文件为docx后,再把每个docx文件转换为md,每一页最后都出现了16,linux则为12,其他文件正常,暂时只发现这个文件,下面是代码
import aspose.words as aw
doc = aw.Document(file_path)
for page in range(0, doc.page_count):
extractedPage = doc.extract_pages(page, 1)
extractedPage.save(f"{result}_output/{file_name}_page{page + 1}.docx")
doc = aw.Document("f"{result}_output/{file_name}_page{page + 1}.docx"")
doc.save("test.md")
@David_Matin 这是页脚中包含页码的字段。在转换文档以获得正确的数字之前,请使用doc.update_fields().
你好,使用这个方法,md文档好像正常了,现在返回 核心信息:
1。那么如何去除页码呢
@David_Matin 如果你不需要页眉/页脚内容,你可以从doc.first_section.clear_headers_footers()部分删除所有页眉/页脚。否则,您可以使用以下代码从页眉/页脚中删除字段:
doc = aw.Document("input.docx")
for section in doc.sections:
section = section.as_section()
footer = section.headers_footers[aw.HeaderFooterType.FOOTER_PRIMARY]
fields = footer.get_child_nodes(aw.NodeType.FIELD_START, True)
for field_start in fields:
field_start = field_start.as_field_start()
field = field_start.get_field()
if field.type is aw.fields.FieldType.FIELD_PAGE:
field.remove()
doc.save("output.md")