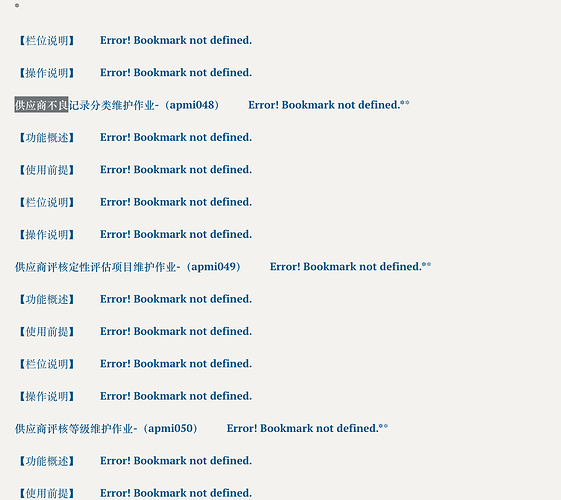
First split the docx document into multiple docx files on a page-by-page basis, and then convert each docx file into a markdown file. In some of these docx files, the converted markdown file contained content that did not exist in the original file.
document = aw.Document(file_path)
for page in range(0, document.page_count):
extractedPage = document.extract_pages(page, 1)
name = f"output/page{page + 1}.docx"
extractedPage.save(name)
document1 = aw.Document(name)
for section in document1.sections:
section = section.as_section()
footer = section.headers_footers[aw.HeaderFooterType.FOOTER_PRIMARY]
if footer:
fields = footer.get_child_nodes(aw.NodeType.FIELD_START, True)
for field_start in fields:
field_start = field_start.as_field_start()
field = field_start.get_field()
if field.type is aw.fields.FieldType.FIELD_PAGE:
field.remove()
document1.update_fields()
save_options = aw.saving.MarkdownSaveOptions()
save_options.image_resolution = 300
document1.save(f"{name}.md", save_options)
error docx:
page21.docx (443.8 KB)
error markdown : https://drive.google.com/file/d/1bn-fJSObOtzC0gFSGQipKzvcd5_P59_w/view?usp=sharing
@David_Matin
Cause
It appears that during the conversion of DOCX files to Markdown, some content is being incorrectly included in the output Markdown files. This issue may arise from how the document is processed, particularly with dynamic content such as page numbers or other fields that may not be relevant in the Markdown format.
Solution
To resolve this issue, ensure that all fields are updated and removed appropriately before saving the document as Markdown. Here’s a refined approach to your existing code:
- Update Fields: Make sure that all fields are updated before saving.
- Remove Unwanted Fields: Specifically target fields that are unnecessary in the Markdown output.
Code
Here’s an updated version of your code snippet:
import aspose.words as aw
document = aw.Document(file_path)
for page in range(document.page_count):
extractedPage = document.extract_pages(page, 1)
name = f"output/page{page + 1}.docx"
extractedPage.save(name)
document1 = aw.Document(name)
# Remove page number fields from footers
for section in document1.sections:
footer = section.headers_footers[aw.HeaderFooterType.FOOTER_PRIMARY]
if footer:
fields = footer.get_child_nodes(aw.NodeType.FIELD_START, True)
for field_start in fields:
field_start = field_start.as_field_start()
field = field_start.get_field()
if field.type is aw.fields.FieldType.FIELD_PAGE:
field.remove()
# Update fields before saving
document1.update_fields()
# Save to Markdown
save_options = aw.saving.MarkdownSaveOptions()
save_options.image_resolution = 300
document1.save(f"{name}.md", save_options)
Next Steps
- Test the updated code with your DOCX files to verify if the unwanted content still appears in the Markdown output.
- If the issue persists, examine the specific content of the DOCX files to identify any patterns or elements that may be causing the problem.
- Review the MarkdownSaveOptions to ensure they are configured correctly for your requirements.
Please implement these changes and let me know if you need further assistance!
@David_Matin the problem occurs because there are REF/PAGEREF fields in your document. REF fields uses bookmarked content as values. When you split the document into pages, some bookmarks might not be available on the particular page, so REF field does not have bookmark to get the value from and shows the error. You can either unlink REF fields in your document to lock them to avoid updating them.
doc = aw.Document("C:\\Temp\\in.docx")
doc.unlink_fields()
doc.save("C:\\temp\\out.md");
or
doc = aw.Document("C:\\Temp\\in.docx")
for f in doc.range.fields :
if f.type == aw.fields.FieldType.FIELD_REF or f.type == aw.fields.FieldType.FIELD_PAGE_REF :
f.is_locked = True
doc.update_fields()
doc.save("C:\\temp\\out.md");
@alexey.noskov Thank u bro! Let me try it
1 Like