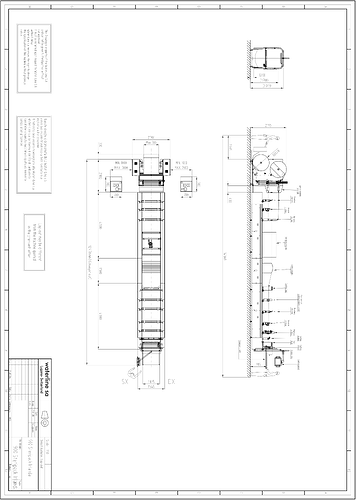
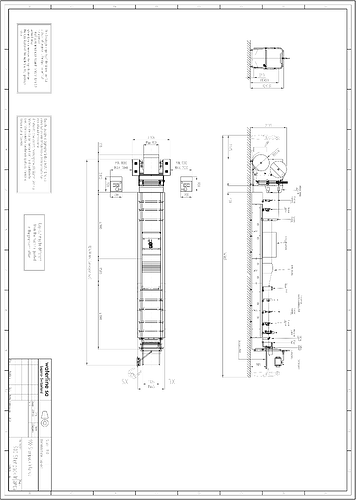
I’m using the api to extract images from a pdf file, but nothing is extracted. But I use aspose.words to convert this pdf to markdown and there are image files in the md file, this is because of what. And, the image obtained after converting to md is not consistent with what is seen in the pdf, the background color becomes black, causing the image recognition to fail.
extract code
file_path = '7cdbfd2e-5893-43f1-a892-4eff48069881.pdf'
document = ap.Document(file_path)
img_dmc_ids = []
for pdfPage in document.pages:
image_list = pdfPage.resources.images
img_base_path = file_path[:file_path.rfind('.pdf')]
img_base_path = f"{img_base_path}_output"
if not os.path.exists(img_base_path):
os.makedirs(img_base_path)
for image in image_list:
# print(image)
try:
image_format = str(image.grayscaled.raw_format).lower()
except:
image_format = "png"
image_name = str(uuid.uuid4()) + '.' + image_format
image_path = image_name
outputImage = io.FileIO(image_path, "w")
# Save output image
image.save(outputImage)
outputImage.close()
convert code
document = aw.Document(source_file)
save_options = aw.saving.MarkdownSaveOptions()
save_options.image_resolution = 300
document.save(f"{result}.md", save_options)
7cdbfd2e-5893-43f1-a892-4eff48069881_page1.pdf (163.5 KB)
@David_Matin
It seems you are experiencing issues with extracting images from a PDF file using Aspose.Words, and you have also noted inconsistencies with the images when converting the PDF to Markdown. Here are some insights that may help you resolve these issues:
-
Image Extraction: The code you provided attempts to extract images from the PDF by accessing the resources of each page. However, if no images are being extracted, it could be due to the way the images are embedded in the PDF. Some images may not be directly accessible as resources, or they may be embedded in a way that requires different handling.
-
Image Format Handling: In your extraction code, you are trying to determine the image format using image.grayscaled.raw_format. If this fails, you default to PNG. Ensure that the images in the PDF are indeed in a format that can be processed. You might want to check if the images are in a supported format or if they are being processed correctly.
-
Markdown Conversion: When converting the PDF to Markdown, the images may be processed differently, which could lead to discrepancies in appearance (like background color changes). This can happen if the conversion process applies different rendering settings or if the images are altered during the conversion.
-
Image Background Color: If the background color of the images changes to black during conversion, it may be due to the color space settings or rendering options used during the conversion process. You can try adjusting the image color space settings in the PdfSaveOptions when saving the document to see if that resolves the issue.
-
Debugging Steps:
- Verify the image extraction logic by checking if the images are indeed present in the PDF using a PDF viewer.
- Experiment with different image formats and extraction methods.
- Review the conversion settings used for Markdown to ensure they align with your expectations for image rendering.
If you continue to face issues, consider providing more details about the specific types of images in the PDF and any error messages you encounter. This information can help in diagnosing the problem more effectively.
Feel free to reach out if you need further assistance!
@David_Matin As I can see you are using Aspose.PDF for image extraction, so I would suggest to report this problem in Aspose.PDF forum.
https://forum.aspose.com/c/pdf/10
You are using Aspose.Words for conversion from PDF to MD. You can use Aspose.Words to extract images from your document:
doc = aw.Document("C:\\Temp\\in.pdf")
i = 0
for s in doc.get_child_nodes(aw.NodeType.SHAPE, True) :
s = s.as_shape()
if s.has_image :
s.image_data.save("C:\\Temp\\image_" + str(i) + aw.FileFormatUtil.image_type_to_extension(s.image_data.image_type))
i = i + 1
@alexey.noskov Why I extracted the picture is so, and in the pdf looks different
@David_Matin Could you please elaborate what you mean? As i can see the image is extracted as is from PDF.
@alexey.noskov
image.jpg (71.2 KB)
This picture, the thumbnail is white background, but after zooming in is a black background, the pdf is seen in the white background
@David_Matin The extracted image actually has transparent background.