根据文档说明,这是获取直接子级的段落,但是实际使用中,会获取到StructuredDocumentTag节点中的段落
那他也不会获取表格里的段落呀,跟文档描述的不符,文档描述是直接子级,而不是后代级段落
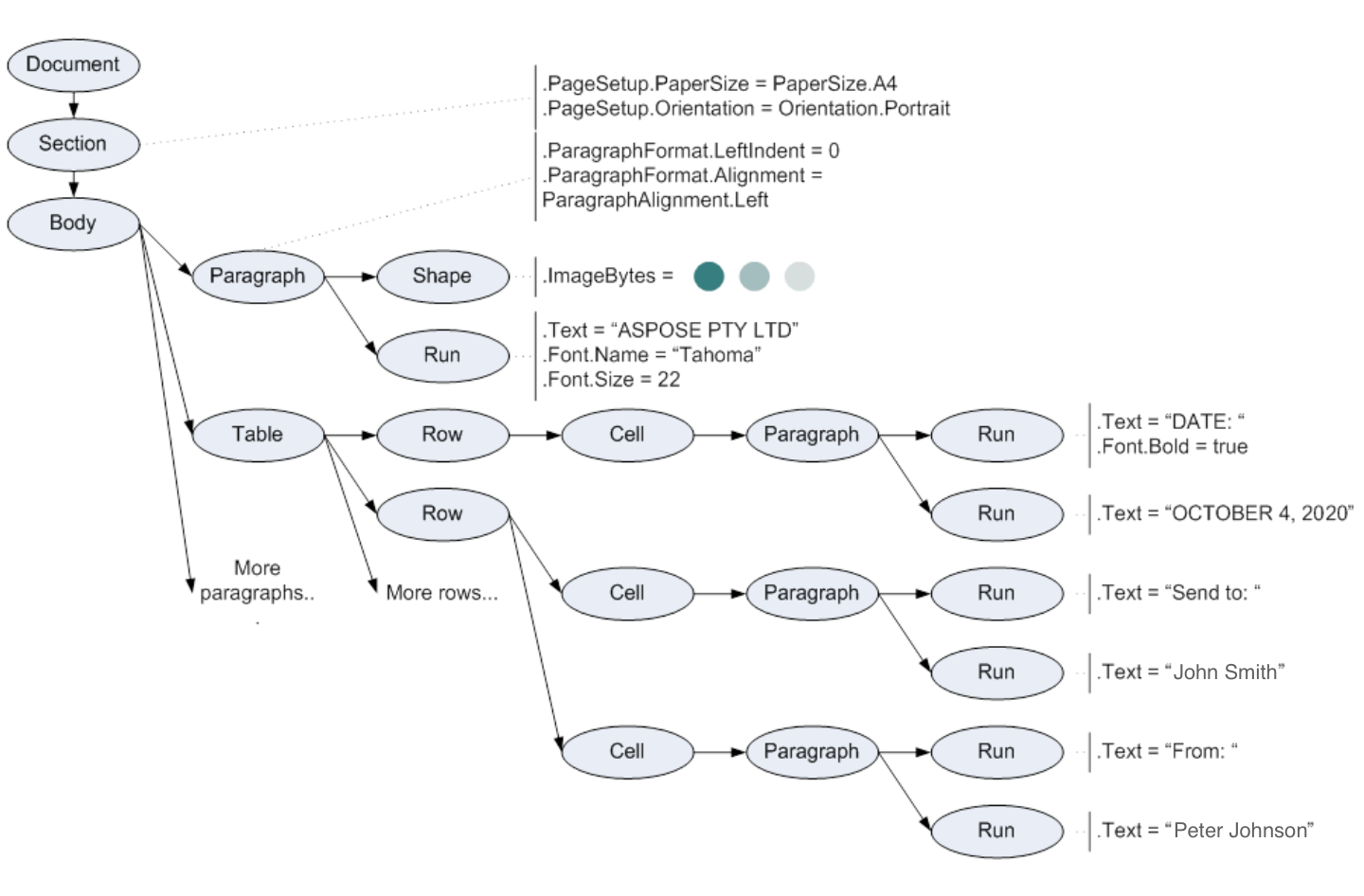
@Crane 正文对象存储正文。 任何故事的文本都由段落和表格组成,分别由块级的段落和表格对象表示。
当您从正文中检索段落时,您将获得当前章节中与表格单元格相关的所有段落。 您可以获取表格或当前单元格来详细说明对象,也可以使用 if (para.getAncestor(NodeType.TABLE) != null) 来避免与表格相关的段落。
请查看我们的文档 - Logical Levels of Nodes in a Document in Java|Aspose.Words for Java

@Crane 好吧,我认为我之前的评论中有一个错误的翻译。你说得对,在描述中有“故事的直接儿童”。
在“Aspose.Words”中,Section节点包含Body和HeaderFooter故事节点。Body对象存储主文本。HeaderFooter对象存储每个页眉和页脚的文本。任何故事的文本都由段落和表格组成,分别由块级的段落和表格对象表示。
因此,当你从正文中检索段落时,根据 DOM,你会得到不包括表格节点的段落:
@vyacheslav.deryushev 但是我通过body.getParagraphs()得到了body中的StructuredDocumentTag节点(比如word自动生成的目录)中的段落,这到底是文档描述错误,还是就是如此。