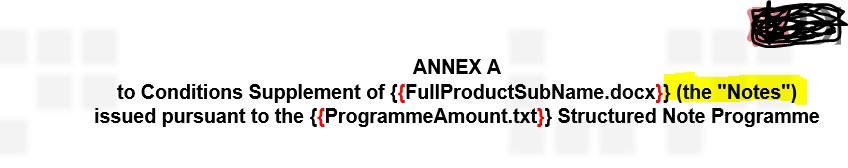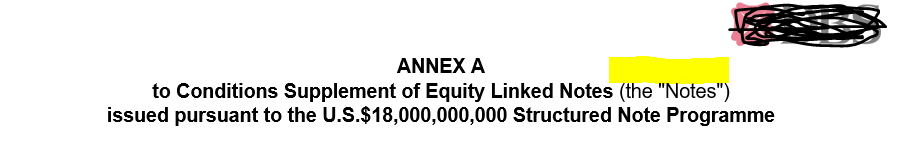Hi Team,
I am trying to replace FullProductSubName.docx document in middle of the paragrapgh using insertInline document method but as shown in below screenshot before replacing this document if we observe the text (“the notes”) is bold but after replaing it not bold.
Before replace of the document :
After replacing the document :
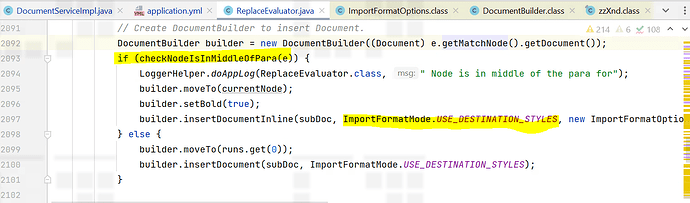
Piece of code using for this is :
Can u plz suggest why documentBuilder is not preserving SourceDocument text bold settings ?
Thanks,
Priyanka.
@priyanka9 It looks like some styles were missed. Try to use ImportFormatMode.KEEP_DIFFERENT_STYLES or ImportFormatMode.KEEP_SOURCE_FORMATTING. With KEEP_SOURCE_FORMATTING you can use
ImportFormatOptions importFormatOptions = new ImportFormatOptions();
importFormatOptions.setSmartStyleBehavior(true);
Hi @vyacheslav.deryushev ,
Thanks for your rly but here most of the cases we need Destination styles thats why we specifically using this.
@priyanka9 Could you please provide the document or a part of the document here, to reproduce the issue?
@priyanka9 Ok, I will wait a file.
Hi @vyacheslav.deryushev ,
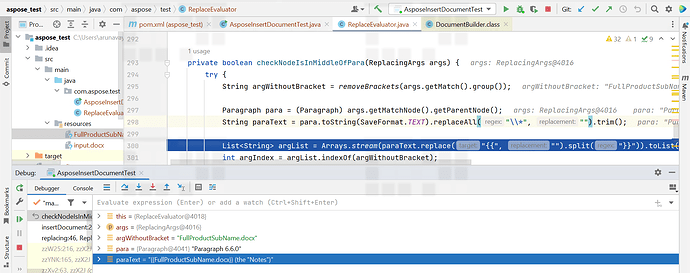
Here is the sample project. Can you plz check and let me know why it is returning is false when i am checking FullProductSubName.docx is in middle of the para or not. Actually it should call insertInline method since this replacement is there in middle of the para.
Sample Project :
aspose_test (2).zip (461.2 KB)
Input and replacement files :
input.docx (76.6 KB)
FullProductSubName (2).docx (19.4 KB)
Thanks,
Priyanka.
@priyanka9 According to your code, it returns false because “FullProductSubName.docx” in the list has a null index. What do you expect from this part of the code?

This happens after replacing. Your current paragraph splits into several. Maybe you need to use para.getParentNode().getText() to get list and check it?
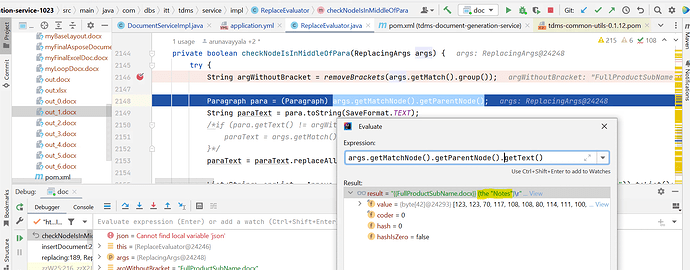
No what i am asking is why below code is returnign extra text ?
below condition should return current node text like FullProductSubName.docx right why its returning the Notes text also ?
Thanks,
Priyanka.
@priyanka9 Thank you for additional information. You are doing a lot of document manipulation in IReplacingCallback, which is not the best practice. I would suggest you to To modify your code like the following:
String regex = "\\{\\{([^}]*)\\}\\}";
Pattern pattern = Pattern.compile(regex);
Document doc = new Document("C:\\Temp\\in.docx");
// 1. Replace all placeholders with themselves to make them to be represented as a single run.
FindReplaceOptions opt = new FindReplaceOptions();
opt.setUseSubstitutions(true);
int matches = doc.getRange().replace(pattern, "$0", opt);
// 2. Check whether there are any placeholders
// (there is no need to get whole document text like in your old code,
// since we have already done this by counting matches)
if (matches > 0)
{
// 3. Get placeholders runs
ArrayList<Run> placeholders = new ArrayList<Run>();
for (Run r : (Iterable<Run>)doc.getChildNodes(NodeType.RUN, true))
{
// Check whether run is a placeholder.
if (pattern.matcher(r.getText()).find())
placeholders.add(r);
}
// 4. Now when we have list of placeholder runs we can replace them.
for (Run placeholder : placeholders)
{
// It is easy to check whether placeholder is the only node in the paragraph
if (placeholder.getParentParagraph().getChildNodes(NodeType.RUN, true).getCount() == 1)
{
// The placeholder is the only child of the parent paragraph.
// .....
}
if (placeholder.getAncestor(NodeType.TABLE) != null)
{
// Placeholder is in table
// .....
}
if (placeholder.getParentParagraph().getLastChild() == placeholder)
{
// Placeholder is at the end of the paragraph.
// .....
}
if (placeholder.getParentParagraph().getFirstChild() == placeholder)
{
// Placeholder is at the beginning of the paragraph.
// .....
}
}
}
Such approach will simplify your code and make the document structure clearer.
Hi @alexey.noskov,
Thanks for your suggestion. Initially since we are new to aspose library we followed some sample projects and implemented this way and later we followed same way and on top of that we added more logic . But now not sure how much impact if we modify the code but definitely will try to change and see if anything is impacting or not.
But before making changes i just want to know what is the difference between the current appraoch and what u suggested ?
In current approach we are calling IReplacingCallback replacing method for every run based on pattern matches and replacing the curent run with replacemnt.
In the suggested approach also same right we are getting all runs together and saving into list and iterating in for loop to get the replacemnt.
Thanks,
Priyanka.
@priyanka9 The difference between your current approach and the suggested approach is that currently you are modifying the document while find/replace operation. Changing the document model while find/replace operation might affect further execution of find/replace operation. In the suggested approach, however, the document model is not manipulated in find/replace operation. So find/replace operation is less error prone. Also in the current approach the placeholder might be represented by several Run nodes and it is required to collect pieces of placeholder in IReplacingCallback implementation. In the suggested approach placeholders are always represented as with a single Run nodes. This simplifies further placeholder processing. So, in my opinion, the suggested approach is less error prone and will give better control over placeholders processing.