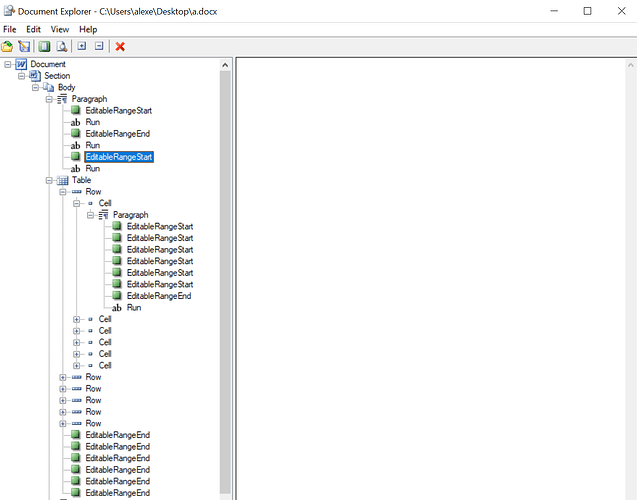
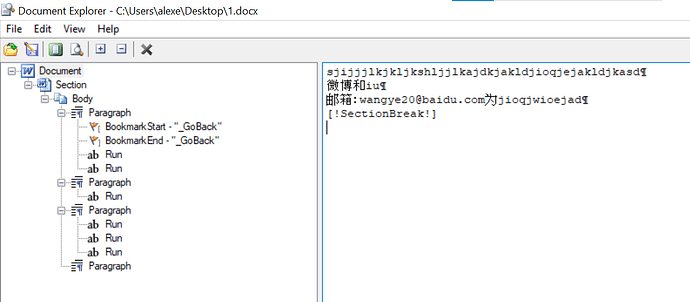
public class NoEditableRangePrinter extends DocumentVisitor {
public NoEditableRangePrinter() {
mBuilder = new StringBuilder();
}
public String toText() {
String result = mBuilder.toString();
// 页脚图片会被识别为 字符串PAGE 过滤掉 问题范本 FBOT20230123
return StringUtils.replace(result, "PAGE", "");
}
public void reset() {
mBuilder.setLength(0);
mInsideEditableRange = true;
}
// <summary>
// Called when an EditableRangeStart node is encountered in the document.
// </summary>
@Override
public int visitDocumentStart(Document doc) throws Exception {
mInsideEditableRange = true;
return VisitorAction.CONTINUE;
}
/**
* VisitorAction
* @param editableRangeStart
* @return
*/
@Override
public int visitEditableRangeStart(EditableRangeStart editableRangeStart) {
mInsideEditableRange = true;
return VisitorAction.CONTINUE;
}
// <summary>
// Called when an EditableRangeEnd node is encountered in the document.
// </summary>
/**
* VisitorAction
* @param editableRangeEnd
* @return
*/
@Override
public int visitEditableRangeEnd(final EditableRangeEnd editableRangeEnd) {
// mBuilder.append(" -- End of editable range -- " + "\r\n");
mInsideEditableRange = false;
return VisitorAction.CONTINUE;
}
// <summary>
// Called when a Run node is encountered in the document. This visitor only records runs that are inside editable ranges.
// </summary>
/**
* doing Visitor
* @param run
* @return
*/
@Override
public int visitRun(final Run run) {
if (!mInsideEditableRange) {
mBuilder.append(StringUtils.trim(run.getText()));
}
return VisitorAction.CONTINUE;
}
private boolean mInsideEditableRange;
private final StringBuilder mBuilder;
}
public class NoEditableRangePrinter extends DocumentVisitor {
public NoEditableRangePrinter() {
mBuilder = new StringBuilder();
}
public String toText() {
String result = mBuilder.toString();
// 页脚图片会被识别为 字符串PAGE 过滤掉 问题范本 FBOT20230123
return result.replace("PAGE", "");
}
public void reset() {
mBuilder.setLength(0);
mEditableRangeNestingList = new ArrayList<EditableRangeEnd>();
}
// <summary>
// Called when an EditableRangeStart node is encountered in the document.
// </summary>
@Override
public int visitDocumentStart(Document doc) throws Exception {
return VisitorAction.CONTINUE;
}
/**
* VisitorAction
* @param editableRangeStart
* @return
*/
@Override
public int visitEditableRangeStart(EditableRangeStart editableRangeStart) throws Exception {
mEditableRangeNestingList.add(editableRangeStart.getEditableRange().getEditableRangeEnd());
System.out.println(editableRangeStart.getId() + " " + mEditableRangeNestingList.size());
return VisitorAction.CONTINUE;
}
// <summary>
// Called when an EditableRangeEnd node is encountered in the document.
// </summary>
/**
* VisitorAction
* @param editableRangeEnd
* @return
*/
@Override
public int visitEditableRangeEnd(final EditableRangeEnd editableRangeEnd) {
mEditableRangeNestingList.remove(editableRangeEnd);
System.out.println(editableRangeEnd.getId() + " " + mEditableRangeNestingList.size());
return VisitorAction.CONTINUE;
}
// <summary>
// Called when a Run node is encountered in the document. This visitor only records runs that are inside editable ranges.
// </summary>
/**
* doing Visitor
* @param run
* @return
*/
@Override
public int visitRun(final Run run) {
if (!isInsideEditableRange()) {
mBuilder.append(run.getText().trim());
}
return VisitorAction.CONTINUE;
}
private boolean isInsideEditableRange()
{
return mEditableRangeNestingList.size()>0;
}
private ArrayList<EditableRangeEnd> mEditableRangeNestingList = new ArrayList<EditableRangeEnd>();
private final StringBuilder mBuilder;
}