例如 1文件。页码是1-5页
2文件。页码是6-10页。以此类推
要根据页码将一个 DOCX 文件拆分成多个新的 DOCX 文件,您可以使用 Aspose.Words 库中的 ExtractPages 方法。这个方法允许您按页码范围提取文档的特定部分。以下是一个示例代码,展示如何将一个文档按页码拆分成多个文件:
using Aspose.Words;
class Program
{
static void Main(string[] args)
{
// 加载源文档
Document doc = new Document("source.docx");
// 定义每个新文档的页码范围
int pageSize = 5; // 每个新文档包含的页数
int totalPages = doc.PageCount; // 获取文档总页数
for (int i = 0; i < totalPages; i += pageSize)
{
// 计算当前页码范围
int startPage = i + 1;
int endPage = Math.Min(i + pageSize, totalPages);
// 提取指定页码范围并保存为新文档
Document newDoc = doc.ExtractPages(startPage - 1, endPage - startPage + 1);
newDoc.Save($"output_{startPage}_{endPage}.docx");
}
}
}
在这个示例中,我们首先加载源文档,然后定义每个新文档的页码范围。接着,我们使用 ExtractPages 方法提取每个范围内的页码,并将其保存为新的 DOCX 文件。您可以根据需要调整 pageSize 变量来改变每个新文档的页数。
通过这种方式,您可以轻松地将一个 DOCX 文件拆分成多个文件,每个文件包含指定的页码范围。
使用python代码。。。。。
@Tiaohh 下面是该代码的 python 版本:
doc = aw.Document("input.docx")
# 定义每份新文件的页数
page_size = 5 # 每份新文件将包含 5 页
total_pages = doc.page_count # 获取文件的总页数
# 循环浏览文件并将其拆分成更小的文件
for i in range(0, total_pages, page_size):
# 计算当前页面范围
start_page = i + 1
end_page = min(i + page_size, total_pages)
# 提取指定页面范围并保存为新文档
new_doc = doc.extract_pages(start_page - 1, end_page - start_page + 1)
new_doc.save(f"output_{start_page}_{end_page}.docx")
文件的几页不一定需要按照第几个的范围进行截取
{‘Table of Content’: (1, 6), ‘F14.1.1.1 受试者分布图’: (7, 7), ‘T14.1.1.1 受试者筛选情况’: (8, 8), ‘T14.1.1.2 分析数据集构成’: (9, 10)}. (1, 6)是第几个到第几页
@Tiaohh 您可以尝试使用类似的方法:
doc = aw.Document("input.docx")
# 将页面范围定义为一个图元列表
page_ranges = [(1, 6), (7, 7)] # 示例: [(start_page1, end_page1), (start_page2, end_page2), ...]
# 循环浏览页面范围并提取指定页面
for i, (start_page, end_page) in enumerate(page_ranges):
# 提取指定页面并保存为新文档
new_doc = doc.extract_pages(start_page - 1, end_page - start_page + 1)
new_doc.save(f"output_{start_page}_{end_page}.docx")
a.docx (6.1 MB)
怎么把 剂量组
24mg QD 的和 24mg BID列进行顺序调整24mg QD在 24mg BID前面 需要适应所有行和列的变动调整
import os
import aspose.words as aw
from bs4 import BeautifulSoup
import re
lic = aw.License()
lic_path = "../Aspose.Total.Product.Family.lic"
lic.set_license(lic_path)
def clean_text(text):
"""清理文本,替换所有形式的NBSP为空格"""
replacements = [
("NBSP", " "),
(" ", " "),
("&NBSP;", " "),
("&Nbsp;", " "),
("\xa0", " "), # Unicode NBSP
(" ", " ") # 将多个空格替换为单个空格
]
for old, new in replacements:
text = text.replace(old, new)
# 处理连续的空格
while " " in text:
text = text.replace(" ", " ")
return text.strip()
def is_row_empty(row):
"""检查行是否为空"""
return all(not td.get_text().strip() for td in row.find_all('td'))
def clean_filename(filename):
"""清理文件名,移除非法字符"""
if not filename:
return ""
# 移除或替换文件名中的非法字符
filename = re.sub(r'[<>:"/\\|?*]', '', filename)
# 限制文件名长度
return filename[:255]
def read_table_docx(rtf_path, a):
_doc = aw.Document(rtf_path)
builder = aw.DocumentBuilder(_doc)
builder.row_format.heading_format = False
# 删除页眉
for section in _doc.sections:
sect = section.as_section()
sect.clear_headers_footers()
# 先尝试从段落获取文件名
filename = a.split('.rtf')[0]
print(filename)
html = _doc.to_string(aw.SaveFormat.HTML)
soup = BeautifulSoup(html, "html.parser")
# 找到所有表格
tables = soup.find_all('table')
if not tables:
print("没有找到表格")
return None, filename
# 如果没有从段落找到文件名,则使用第一个表格的第一行
if not filename:
first_row = tables[0].find('tr')
if first_row:
first_cell = first_row.find('td')
if first_cell:
filename = clean_text(first_cell.get_text().strip())
# 如果只有一个表格,只进行文本清理
if len(tables) == 1:
new_soup = BeautifulSoup("<table></table>", "html.parser")
new_table = new_soup.table
# 处理原表格中的每一行
for row in tables[0].find_all('tr'):
new_row = new_soup.new_tag('tr')
for td in row.find_all('td'):
new_td = new_soup.new_tag('td')
if 'colspan' in td.attrs:
new_td['colspan'] = td['colspan']
if 'rowspan' in td.attrs:
new_td['rowspan'] = td['rowspan']
new_td.string = clean_text(td.get_text())
new_row.append(new_td)
new_table.append(new_row)
return str(new_table), filename
# 创建新的表格
new_soup = BeautifulSoup("<table></table>", "html.parser")
new_table = new_soup.table
# 获取第一个表格的所有行
first_table = tables[0]
first_table_rows = first_table.find_all('tr')
# 保存第一个表格的最后一行
last_row_of_first = first_table_rows[-1]
# 复制第一个表格的内容(除了最后一行)
for row in first_table_rows[:-1]:
new_row = new_soup.new_tag('tr')
for td in row.find_all('td'):
new_td = new_soup.new_tag('td')
if 'colspan' in td.attrs:
new_td['colspan'] = td['colspan']
if 'rowspan' in td.attrs:
new_td['rowspan'] = td['rowspan']
new_td.string = clean_text(td.get_text())
new_row.append(new_td)
new_table.append(new_row)
# 处理其他表格(从第二个表格开始)
for table in tables[2:]:
rows = table.find_all('tr')
if len(rows) > 2: # 确保表格有足够的行
# 添加中间的行(去掉前3行和最后一行),同时跳过空行
for row in rows[1:]: # 从第4行开始(索引3)
if not is_row_empty(row): # 跳过空行
new_row = new_soup.new_tag('tr')
for td in row.find_all('td'):
new_td = new_soup.new_tag('td')
if 'colspan' in td.attrs:
new_td['colspan'] = td['colspan']
if 'rowspan' in td.attrs:
new_td['rowspan'] = td['rowspan']
new_td.string = clean_text(td.get_text())
new_row.append(new_td)
new_table.append(new_row)
# 最后添加第一个表格的最后一行
new_row = new_soup.new_tag('tr')
for td in last_row_of_first.find_all('td'):
new_td = new_soup.new_tag('td')
if 'colspan' in td.attrs:
new_td['colspan'] = td['colspan']
if 'rowspan' in td.attrs:
new_td['rowspan'] = td['rowspan']
new_td.string = clean_text(td.get_text())
new_row.append(new_td)
new_table.append(new_row)
# 重新排序行和列
new_table = reorder_rows_and_columns(new_table)
return str(new_table), filename
def reorder_rows_and_columns(table):
"""重新排序行和列,将包含“24mg QD”的行和列放在前面,将包含“24mg BID”的行和列放在后面"""
rows = table.find_all('tr')
if not rows:
return table
header_row = rows[0]
data_rows = rows[1:]
qd_rows = []
bid_rows = []
other_rows = []
for row in data_rows:
cells = row.find_all('td')
if cells:
text = clean_text(" ".join(cell.get_text() for cell in cells))
if "24mg QD" in text:
qd_rows.append(row)
elif "24mg BID" in text:
bid_rows.append(row)
else:
other_rows.append(row)
sorted_rows = [header_row] + qd_rows + other_rows + bid_rows
new_soup = BeautifulSoup("<table></table>", "html.parser")
new_table = new_soup.table
for row in sorted_rows:
new_table.append(row)
# 重新排序列
for row in new_table.find_all('tr'):
cells = row.find_all('td')
qd_cells = []
bid_cells = []
other_cells = []
for cell in cells:
text = clean_text(cell.get_text())
if "24mg QD" in text:
qd_cells.append(cell)
elif "24mg BID" in text:
bid_cells.append(cell)
else:
other_cells.append(cell)
sorted_cells = qd_cells + other_cells + bid_cells
# 清空原有的单元格
for cell in cells:
cell.extract()
# 重新添加排序后的单元格
for cell in sorted_cells:
row.append(cell)
return new_table
def get_unique_filename(output_dir, base_name):
"""
生成唯一的文件名,如果文件名已存在则添加序号
"""
counter = 1
file_name = f"{base_name}.txt"
file_path = os.path.join(output_dir, file_name)
# 如果文件已存在,添加序号直到找到唯一的文件名
while os.path.exists(file_path):
file_name = f"{base_name}_{counter}.txt"
file_path = os.path.join(output_dir, file_name)
counter += 1
return file_path
def process_directory():
input_dir = "./CS32582-101_RTF"
output_dir = "./CS32582-101_RTF_txt"
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 记录处理的文件数量
total_files = 0
processed_files = 0
failed_files = []
skipped_files = []
# 遍历目录下的所有文件
for filename in os.listdir(input_dir):
if filename.lower().endswith(('.docx', '.doc', '.rtf')):
total_files += 1
input_path = os.path.join(input_dir, filename)
try:
# 处理文件
result, new_filename = read_table_docx(input_path, filename)
# 获取唯一的输出文件路径
output_path = get_unique_filename(output_dir, filename.split('.rtf')[0])
# 保存内容,即使result为空
with open(output_path, 'w', encoding='utf-8') as f:
if result:
f.write(result)
else:
f.write("") # 写入空字符串
skipped_files.append(filename) # 记录没有内容的文件
processed_files += 1
print(f"成功处理文件: {filename}")
print(f"保存到: {output_path}")
except Exception as e:
failed_files.append((filename, str(e)))
print(f"处理文件 {filename} 时出错: {str(e)}")
# 打印处理统计
print("\n处理统计:")
print(f"总文件数: {total_files}")
print(f"成功处理: {processed_files}")
print(f"处理失败: {len(failed_files)}")
print(f"无内容文件: {len(skipped_files)}")
# 打印失败的文件列表
if failed_files:
print("\n失败的文件:")
for fail_file, error in failed_files:
print(f"文件: {fail_file}")
print(f"错误: {error}\n")
# 打印无内容的文件列表
if skipped_files:
print("\n无内容的文件:")
for skip_file in skipped_files:
print(f"文件: {skip_file}")
# 列出输入目录中的所有文件
print("\n输入目录中的文件:")
input_files = [f for f in os.listdir(input_dir) if f.lower().endswith(('.docx', '.doc', '.rtf'))]
for f in input_files:
print(f)
# 列出输出目录中的所有文件
print("\n输出目录中的文件:")
output_files = [f for f in os.listdir(output_dir) if f.endswith('.txt')]
for f in output_files:
print(f)
if __name__ == "__main__":
process_directory()
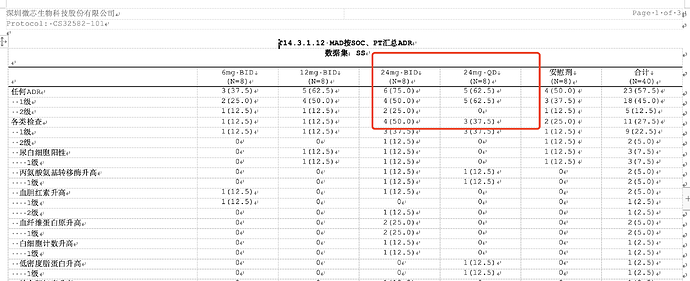
我需要对24mg QD和24mg BID行和列数据进行互换位置
表格需要处理成24mg QD在24mg BID前面
@Tiaohh 根据您提供的带有表格数据的图像,您可以尝试使用以下代码交换两列:
doc = aw.Document("input.docx")
table = doc.get_child(aw.NodeType.TABLE, 0, True).as_table()
# 搜索包含 "24 毫克 BID "和 "24 毫克 QD "的列
search_text_bid = "24mg BID"
search_text_qd = "24mg QD"
col_bid = self.find_cell_by_text(table, search_text_bid)
col_qd = self.find_cell_by_text(table, search_text_qd)
# 交换列
self.swap_columns(table, col_bid, col_qd)
doc.save("output.docx")
def find_cell_by_text(self, table, search_text):
for row in table.rows:
row = row.as_row()
for cell_idx, cell in enumerate(row.cells):
# Get the cell text and remove special characters
cell_text = cell.get_text().replace("\x07", "").strip()
if cell_text == search_text:
return cell_idx
return None
def swap_columns(self, table, col1, col2):
for row in table.rows:
row = row.as_row()
cell1 = row.cells[col1]
cell2 = row.cells[col2]
# 克隆单元格内容以保留格式
cell1_content = cell1.first_paragraph.clone(True)
cell2_content = cell2.first_paragraph.clone(True)
# 交换内容
cell1.remove_all_children()
cell1.append_child(cell2_content)
cell2.remove_all_children()
cell2.append_child(cell1_content)
如果是行呢??????????
@Tiaohh 不幸的是,我无法理解(或者可能无法正确翻译)你问的问题。您有一个表,其中有两列需要交换的数据。您可以使用提供的代码来交换此列。下一步,您可以使用此表执行所需的操作(解析数据或其他操作)。