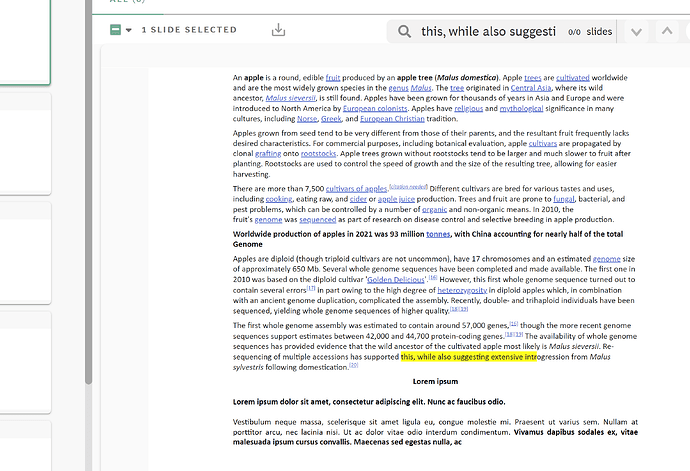
Hi, I have a docx file (please see the attachment) and wants to extract content based on page number? For example, if I wanted to extract the content from pages 1 and 3?
I am aware about the fact that “Word document is flow document and does not contain any information about its layout into lines and pages. Therefore, technically there is no “Page” concept in Word document. Aspose.Words uses our own Rendering Engine to layout documents into pages.”
So, have used DocumentPageSplitter to address this. But, still some of the data is getting copied from the adjacent pages. Please find below the actual document and the extracted document with Pages 1 and 3.
Note: Aspose word version used: name: ‘aspose-words’, version: ‘23.4’
Language used: Java
extracted Sample test doc.docx (15.7 KB)
Sample test doc.docx (54.2 KB)
Code piece:
String extractPages(ClippingRequestMessage requestMessage, File originalFile, List<Integer> pages) throws Exception {
Document document = new Document(originalFile.getAbsolutePath());
log.info("Document loaded: {}", originalFile.length());
log.info("Total page numbers: {}", document.getPageCount());
DocumentPageSplitter splitter = new DocumentPageSplitter(document);
Document tempDocument = new Document();
int counter = 0;
sort(pages);
for (int pageNum : pages) {
counter++;
if (counter == 1) {
tempDocument = splitter.getDocumentOfPage(pageNum);
cleanUpDocument(tempDocument);
} else {
Document tempNewDocument = splitter.getDocumentOfPage(pageNum);
cleanUpDocument(tempNewDocument);
tempDocument.appendDocument(tempNewDocument, ImportFormatMode.KEEP_DIFFERENT_STYLES);
}
}
log.info("Document created");
String tempClippedDocument = TempFileHelper.getTempClippedFile(requestMessage);
tempDocument.save(tempClippedDocument);
return tempClippedDocument;
}
I tried upgrading the version to the latest 23.11 but it does not support “DocumentPageSplitter”. Is there any other alternate to this which fixes the issue as well supports the latest version of aspose. Can you please help on this.
Thank you!