Hi Alexey, Pls find the attached docx file, extracted html in json file and the extraction code.
Shared docx file have section named “PURPOSE”, the content under the said section has 3 different fonts(12,11 and 14pt), but the extracted content didn’t retain all such information. My expectation is to retain the font size, specific to the sub paragraph.
public static void docxparsing(string filename, string outputpath = "")
{
try
{
List<DocLinkData> lst = new List<DocLinkData>();
// Load the document
Document doc = new Document(filename);
doc.UpdateFields();
// Create an HTML save options object to configure the HTML output
HtmlSaveOptions saveOptions = new HtmlSaveOptions
{
ExportHeadersFootersMode = ExportHeadersFootersMode.None,
PrettyFormat = true,
ExportImagesAsBase64 = true,
};
List<SectionJSON> lstJSon = new List<SectionJSON>();
foreach (Field field in doc.Range.Fields)
{
if (field.Type.Equals(FieldType.FieldHyperlink))
{
FieldHyperlink hyperlink = (FieldHyperlink)field;
if (hyperlink.SubAddress != null && hyperlink.SubAddress.StartsWith("_Toc"))
{
// Get the bookmark and the paragraph it points to
Bookmark bm = doc.Range.Bookmarks[hyperlink.SubAddress];
DocLinkData obj = new DocLinkData();
obj.Name = bm.Text;
obj.SubAddress = hyperlink.SubAddress;
lst.Add(obj);
}
}
}
#region Fields
// Iterate through the fields in the document
foreach (Field field in doc.Range.Fields)
{
string Headerhtml = string.Empty;
string HeaderText = string.Empty;
string Contenthtml = string.Empty;
if (field.Type.Equals(FieldType.FieldHyperlink))
{
FieldHyperlink hyperlink = (FieldHyperlink)field;
if (hyperlink.SubAddress != null && hyperlink.SubAddress.StartsWith("_Toc"))
{
// Get the paragraph containing the TOC item
Paragraph tocItem = (Paragraph)field.Start.GetAncestor(NodeType.Paragraph);
if (tocItem != null)
{
SectionJSON obj = new SectionJSON();
#region HeaderContent
// Get the bookmark and the paragraph it points to
Bookmark bm = doc.Range.Bookmarks[hyperlink.SubAddress];
if (bm != null)
{
Paragraph pointer = (Paragraph)bm.BookmarkEnd.GetAncestor(NodeType.Paragraph);
if (pointer != null)
{
// Save the paragraph content as HTML
Node[] nodes = { pointer.Clone(true) };
Document tempDoc = new Document();
tempDoc.FirstSection.Body.AppendChild(tempDoc.ImportNode(pointer, true));
string htmlContent;
using (System.IO.MemoryStream htmlStream = new System.IO.MemoryStream())
{
tempDoc.Save(htmlStream, saveOptions);
htmlContent = System.Text.Encoding.UTF8.GetString(htmlStream.ToArray());
}
var doc1 = new HtmlAgilityPack.HtmlDocument();
doc1.LoadHtml(htmlContent);
// Select the body tag
var bodyNode = doc1.DocumentNode.SelectSingleNode("//body");
Headerhtml = bodyNode.InnerHtml;
//HeaderText = bodyNode.InnerText.Replace("1.2", "").Replace("1.1", "").Replace("1.1", "").Replace("1.0", "").Replace("\r", "").Replace("\t", "").Replace("\n", "").Replace(" ", "").TrimStart().TrimEnd();
HeaderText = bm.Text;
obj.Heading = HeaderText;
}
}
#endregion HeaderContent
#region SectionContent
// Get the bookmark and the paragraph it points to
Bookmark bm2 = doc.Range.Bookmarks[hyperlink.SubAddress];
if (bm2 != null)
{
Paragraph pointer1 = (Paragraph)bm2.BookmarkStart.GetAncestor(NodeType.Paragraph);
Section section1 = (Section)bm2.BookmarkStart.GetAncestor(NodeType.Section);
if (pointer1 != null && section1 != null)
{
// Create a temporary document to hold the section content
Document tempDoc = new Document();
Section tempSection = tempDoc.ImportNode(section1, false) as Section;
tempDoc.AppendChild(tempSection);
// Initialize the body of the temp section
if (tempSection.Body == null)
{
tempSection.EnsureMinimum();
}
// Collect all nodes from the bookmark's paragraph to the next TOC item or end of the section
bool isCollecting = false;
bool firstNodeCollected = false;
foreach (Node node in section1.Body)
{
if (node == pointer1)
isCollecting = true;
if (isCollecting)
{
if (firstNodeCollected)
{
// Check if the node is another TOC bookmark
if (node.NodeType == NodeType.Paragraph)
{
Paragraph paragraph = (Paragraph)node;
foreach (Bookmark bookmarkStart in paragraph.Range.Bookmarks)
{
var bookmarktext = bookmarkStart.Text.TrimStart().TrimEnd();
if (bookmarktext.Contains("\r"))
{
string[] lines = bookmarktext.Split(new[] { "\r", "\n", "\r\n" }, StringSplitOptions.None);
bookmarktext = lines[lines.Length - 1];
}
var fieldname = ParseRevisionHistory(field.DisplayResult);
var templist = lst.Where(x => x.Name == bookmarktext).ToList();
if (bookmarkStart.Name.StartsWith("_Toc") && bookmarkStart.BookmarkStart != bm2.BookmarkStart && HeaderText != bookmarkStart.Text.TrimStart().TrimEnd() && templist.Count != 0)
{
isCollecting = false;
break;
}
}
if (!isCollecting)
break;
}
if (node.NodeType == NodeType.Paragraph)
{
Paragraph para = (Paragraph)node;
ReplaceTextInRuns(para);
}
else if (node.NodeType == NodeType.Table)
{
Table table = (Table)node;
foreach (Row row in table.Rows)
{
foreach (Cell cell in row.Cells)
{
foreach (Paragraph para in cell.Paragraphs)
{
ReplaceTextInRuns(para); // Handle text inside table cells
}
}
}
}
tempSection.Body.AppendChild(tempDoc.ImportNode(node, true));
}
else
{
firstNodeCollected = true;
}
}
}
// Save the collected content as HTML
string htmlContent;
using (System.IO.MemoryStream htmlStream = new System.IO.MemoryStream())
{
tempDoc.Save(htmlStream, saveOptions);
htmlContent = System.Text.Encoding.UTF8.GetString(htmlStream.ToArray());
}
var doc1 = new HtmlAgilityPack.HtmlDocument();
doc1.LoadHtml(htmlContent);
// Select the body tag
var bodyNode = doc1.DocumentNode.SelectSingleNode("//body");
Contenthtml = bodyNode.InnerHtml;
// Load the HTML into HtmlDocument objects
var headerDoc = new HtmlDocument();
var contentDoc = new HtmlDocument();
headerDoc.LoadHtml(Headerhtml);
contentDoc.LoadHtml(Contenthtml);
HtmlDocument document = new HtmlDocument();
document.LoadHtml(Contenthtml);
// Select all div nodes
HtmlNodeCollection divNodes = document.DocumentNode.SelectNodes("//div");
if (divNodes != null && divNodes.Count > 0)
{
// Remove the first div node
divNodes[0].Remove();
}
// Get the updated HTML
string updatedHtml = document.DocumentNode.OuterHtml;
obj.Content = SpecialCharacterReplaceValuesInHtml(updatedHtml);
}
}
#endregion SectionContent
lstJSon.Add(obj);
}
} // End If
} // End If
} // End Foreach
#endregion Fields
doc.Save(filename);
string jsonString = Newtonsoft.Json.JsonConvert.SerializeObject(lstJSon);
// Step 3: Write the JSON data to a file
File.WriteAllText(outputpath, jsonString);
}
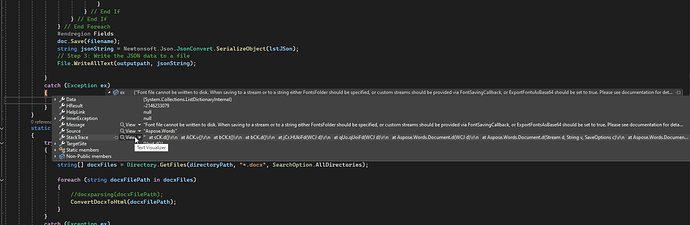
catch (Exception ex)
{
Console.WriteLine($"docxparsing Method Error: {ex.Message}");
}
}
HTML JSON:
[{"Heading":"PURPOSE","Content":"<br style=\"page-break-before:always; clear:both; mso-break-type:section-break\"><div><p><span style=\"-aw-import:ignore\"></span></p><p style=\"margin-left:36pt; margin-bottom:4.95pt; font-size:14pt\"><span style=\"font-size:12pt\">The OQ Protocol section of this qualiication package aims to validate the operational performance of the Equipment System under specified conditions and operational parameters. This includes confirming that all critical functions and features of the Equipment System perform as intended and meet predetermined specifications. The OQ Protocol will assess the system’s response to normal operating conditions, verify that all safety interlocks and alarms function correctly, and ensure that the Equipment System can consistently perform its intended operations, including flow rates, temperatures, pressures, and cycle times. Additionally, the OQ Protocol documentation will include results from performance testing, calibration checks, and any necessary adjustments made to optimize performance</span><span>. Overall, the OQ Protocol ensures that the Equipment System is capable of operate safer and effectively throughout its intended life. </span></p></div>"},{"Heading":"SCOPE","Content":"<br style=\"page-break-before:always; clear:both; mso-break-type:section-break\"><div><p><span style=\"-aw-import:ignore\"></span></p><p style=\"margin-left:36pt; margin-bottom:4.95pt\"><span>The Operational Qualification (OQ) Protocol for the Clean-In-Process (CIP) Skid 1500L establishes and validates its operational capabilities, ensuring consistent and reliable cleaning of manufacturing vessels in a fill/finish facility. The protocol confirms that the equipment meets its intended use by thoroughly evaluating all critical performance parameters, operational controls, and safety mechanisms. It validates that the system is capable of delivering reproducible cleaning outcomes for high-capacity manufacturing vessels, ensuring compliance with stringent regulatory and quality standards in pharmaceutical manufacturing.</span></p><p style=\"margin-left:36pt; margin-bottom:4.95pt\"><span style=\"-aw-import:ignore\"></span></p><p style=\"margin-left:36pt; margin-bottom:4.95pt; font-size:14pt\"><span>The scope of this qualification includes:</span></p><ol style=\"margin:0pt; padding-left:0pt\"><li style=\"margin-left:68pt; padding-left:4pt\"><span>Validation of Critical Parameters:</span><ol style=\"margin-right:0pt; margin-left:0pt; padding-left:0pt; list-style-type:lower-latin\"><li style=\"margin-left:31.33pt; padding-left:4.67pt\"><span>Flow Rates and Pressure Management: Testing and verification of flow rates across the operational range (minimum to maximum vessel capacities) to ensure effective cleaning. Validation of pressure monitoring and control systems to maintain consistent cleaning efficiency without damaging vessel surfaces.</span></li><li style=\"margin-left:32pt; padding-left:4pt\"><span>Temperature Profiles: Verification of the heating system's ability to achieve and maintain target temperatures for hot water or chemical cleaning cycles, ensuring uniform temperature distribution across vessel surfaces.</span></li><li style=\"margin-left:31.33pt; padding-left:4.67pt\"><span>Chemical Dosing and Dilution: Accurate delivery and mixing of cleaning agents to specified concentrations, ensuring effective removal of residues without compromising vessel integrity or cross-contaminating subsequent batches.</span></li></ol></li></ol><p style=\"margin-left:36pt; margin-bottom:4.95pt\"><span style=\"-aw-import:ignore\"></span></p><ol start=\"2\" style=\"margin:0pt; padding-left:0pt\"><li style=\"margin-left:68pt; padding-left:4pt\"><span>Operational Scenarios</span></li></ol><p style=\"margin-left:90pt\"><span>The OQ Protocol assesses the CIP Skid’s performance under various operational conditions:</span></p><ol style=\"margin:0pt; padding-left:0pt; list-style-type:lower-latin\"><li style=\"margin-left:103.33pt; padding-left:4.67pt\"><span>Routine Operations: Validation of cleaning cycles for vessels ranging in size and complexity, ensuring scalability up to 1500L.</span></li><li style=\"margin-left:104pt; padding-left:4pt\"><span>Stress Testing:</span><span style=\"font-weight:bold\"> </span><span>Assessment of system performance under prolonged continuous operation to simulate peak production scenarios in the fill/finish facility.</span></li><li style=\"margin-left:103.33pt; padding-left:4.67pt\"><span>Emergency Recovery:</span><span style=\"font-weight:bold\"> </span><span>Testing the system’s ability to resume operation after simulated power outages, emergency stops, or unexpected interruptions.</span></li></ol><p><span style=\"-aw-import:ignore\"></span></p></div>"}]
Section Style Doc (1).docx (15.2 KB)