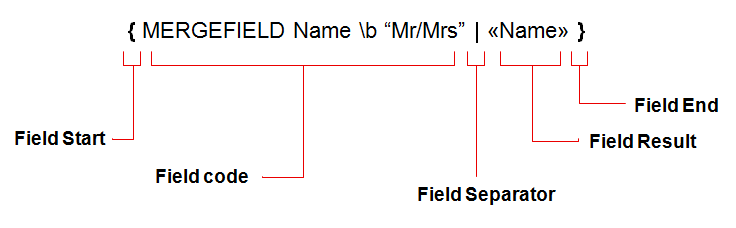
Here is a VSTO function that I’m trying to translate to Aspose.Words:
public Field GetNextField(Range rng, int selStart)
{
var NextField = (from f in rng.Fields
where f.Start > selStart
orderby f.Code.Start
select f).FirstOrDefault();
return NextField;
}
It is a bit of LINQ, but the basic idea is to get the first Field object that appears after the specified selStart. In VSTO, I could do this simply by comparing Field.Start to selStart, but in Aspose.Words, Field object’s Start property doesn’t seem to provide its starting/ending positions.
There is no integer property that specifies position of a particular node in the Range. In your case you can use either Node.NextSibling property or Node.NextPreOrder method to get nodes that follows the specified one. But, could you please describe the ultimate goal? I am sure we will find a way to achieve what is required.
Our current application design requires position information of the Field objects, like VSTO provides. I have given it some more thought and I think I can live without integer position by moving away from the Iterator pattern we’re currently using. I’ll get back if that doesn’t work for us.
@Shujee Sure, please, feel free to ask in case of any issues.
I think in your case you can consider using DocumentVisitor approach to step through the document tree.
So I spent more time with it. One thing that we are particularly missing in Aspose.Words is the Range object functionality. Our VSTO add-in makes heavy use of the Range object for things like selecting and formatting portions of a paragraph (one or a few words for example turned to bold and/or italic) and then moving cursor forward. This is something I haven’t been able to achieve in Aspose.Words.
Another thing I’m struggling with is the absolute position of a field or table object within the document. We use this information to display a vertical bar to the left of the document marking the “percent positions” of these elements. You may have seen this kind of vertical bar in Visual Studio or Git tools or in WinMerge etc. Now this bar can only be constructed if we know the position of these elements relative to the entire document body.
@Shujee Unfortunately, Aspose.Words does not provide such reach Range functionality, like MS Word does. However, you can easily format text using Aspose.Words. Text formatting is set per Run node. Also, if you need to format some particular text that matches regular expression or text pattern. You can achieve this using Range.Raplace functionality. For example the following code makes the matched text bold and italic:
Document doc = new Document(@"C:\Temp\in.docx");
FindReplaceOptions options = new FindReplaceOptions();
// Specify font settings that should be applied to the matched text.
options.ApplyFont.Bold = true;
options.ApplyFont.Italic = true;
// Since we wil use regular expression to match text,
// enable substututuins option to repace text with the same that is matched.
options.UseSubstitutions = true;
// This will make bold and italic all words that are 7 characters or longer.
doc.Range.Replace(new Regex("[a-zA-Z]{7,}"), "$0", options);
doc.Save(@"C:\Temp\out.docx");
In general in Aspose.Words you should rely on Document Object Model when work with document content.
Regarding absolute position of nodes in the document, you can use LayoutCollector and LayoutEnumerator classes. Here is example that draws a vertical line in MS Word document where tables are located:
Document doc = new Document(@"C:\Temp\in.docx");
LayoutCollector collector = new LayoutCollector(doc);
LayoutEnumerator enumerator = new LayoutEnumerator(doc);
// Get all tables rows
NodeCollection rows = doc.GetChildNodes(NodeType.Row, true);
foreach (Row r in rows)
{
// LayoutCollector and LayoutEnumerator do not work with nodes in header and footer of the document.
if (r.GetAncestor(NodeType.HeaderFooter) != null)
continue;
// Move enumerator to the paragraph in the row.
enumerator.Current = collector.GetEntity(r.FirstCell.FirstParagraph);
// Move to Row entity
while (enumerator.Type != LayoutEntityType.Row)
enumerator.MoveParent();
Console.WriteLine(enumerator.Type);
// Now we can get rectangle the current entity occupies.
RectangleF paraRect = enumerator.Rectangle;
// Create a vertical line with height of the paragraph and place it left from the paragraph.
Shape line = new Shape(doc, ShapeType.Line);
line.Height = paraRect.Height;
line.Width = 0;
line.WrapType = WrapType.None;
line.RelativeHorizontalPosition = RelativeHorizontalPosition.Page;
line.RelativeVerticalPosition = RelativeVerticalPosition.Page;
line.Top = paraRect.Top;
line.Left = paraRect.Left - 20; // Move line a little left.
line.StrokeColor = Color.Green;
line.StrokeWeight = 5;
line.IsLayoutInCell = false;
((Paragraph)r.ParentTable.NextSibling).AppendChild(line);
}
doc.Save(@"C:\Temp\out.docx");
Here are input and output documents. in.docx (13.7 KB) out.docx (11.5 KB)
Thanks Alexey, those solutions give me a ray of hope.
I’m experimenting with LayoutEnumerator at the moment. For some reason, collector.GetEntity(r) in your code returns null when I try it with StructuredDocumentTag elements. Can you please check what I’m doing wrong here?
@Shujee Thank you for additional information. As described in the remarks of LayoutCollector.GetEntity method, it can be used for Paragraph or for inline nodes. So it does not work for StructuredDocumentTag. So in your case, you can try processing StructuredDocumentTag content. I have created a code example that demonstrates the technique:
Document doc = new Document(@"C:\Temp\in.docx");
LayoutCollector collector = new LayoutCollector(doc);
LayoutEnumerator enumerator = new LayoutEnumerator(doc);
// First get top level paragraphs on each page. Shapes in SDT and tables are layout differently,
// and to properly place shape it is required to add them to the top level paragraph.
Dictionary<int, Paragraph> topLevelParagraphs = new Dictionary<int, Paragraph>();
List<Paragraph> paragraphs = doc.GetChildNodes(NodeType.Paragraph, true)
.Cast<Paragraph>().Where(p => p.ParentNode.NodeType == NodeType.Body).ToList();
foreach (Paragraph p in paragraphs)
{
int pageIndex = collector.GetStartPageIndex(p);
if (!topLevelParagraphs.ContainsKey(pageIndex))
topLevelParagraphs.Add(pageIndex, p);
}
// Get all tables SDTs
NodeCollection sdts = doc.GetChildNodes(NodeType.StructuredDocumentTag, true);
foreach (StructuredDocumentTag tag in sdts)
{
// LayoutCollector and LayoutEnumerator do not work with nodes in header and footer of the document.
if (tag.GetAncestor(NodeType.HeaderFooter) != null)
continue;
foreach (Node child in tag.ChildNodes)
{
if (child.NodeType == NodeType.Paragraph || child.NodeType == NodeType.Table)
HighightSdtContent(child, collector, enumerator, topLevelParagraphs);
}
}
doc.Save(@"C:\Temp\out.docx");
private static void HighightSdtContent(Node node, LayoutCollector collector,
LayoutEnumerator enumerator, Dictionary<int, Paragraph> topLevelParagraphs)
{
if (node.NodeType != NodeType.Paragraph && node.NodeType != NodeType.Table)
throw new ArgumentException("Only Paragraph and Table nodes are supported.");
if (node.NodeType == NodeType.Paragraph)
{
enumerator.Current = collector.GetEntity(node);
Shape line = CreateShape(node.Document, enumerator.Rectangle);
if(topLevelParagraphs.ContainsKey(enumerator.PageIndex))
topLevelParagraphs[enumerator.PageIndex].PrependChild(line);
}
else if (node.NodeType == NodeType.Table)
{
Table table = (Table)node;
foreach (Row r in table.Rows)
{
// Move enumerator to the paragraph in the row.
enumerator.Current = collector.GetEntity(r.FirstCell.FirstParagraph);
// Move to Row entity
while (enumerator.Type != LayoutEntityType.Row)
enumerator.MoveParent();
Shape line = CreateShape(node.Document, enumerator.Rectangle);
if (topLevelParagraphs.ContainsKey(enumerator.PageIndex))
topLevelParagraphs[enumerator.PageIndex].PrependChild(line);
}
}
}
private static Shape CreateShape(DocumentBase doc, RectangleF paraRect)
{
// Create a vertical line with height of the paragraph and place it left from the paragraph.
Shape line = new Shape(doc, ShapeType.Line);
line.Height = paraRect.Height;
line.Width = 0;
line.WrapType = WrapType.None;
line.RelativeHorizontalPosition = RelativeHorizontalPosition.Page;
line.RelativeVerticalPosition = RelativeVerticalPosition.Page;
line.Top = paraRect.Top;
line.Left = 30;
line.StrokeColor = Color.Green;
line.StrokeWeight = 5;
line.IsLayoutInCell = false;
return line;
}
Thanks again. This is getting close. One thing that I have noticed; the above code does not work with ContentControls that span multiple pages (or contain more than one paragraph). I’m attaching sample document.
Also does it make things any simple if I simply want to fetch ContentControl’s height and not actually show that green line? I mean do we still have to iterate through the child paragraphs/table rows?
Unfortunately, no, this does not make the things any simpler. As you know MS Word documents are flow document and there is not information about elements size in it (except shapes of course). So to calculate Height of content control you have to calculate height of it’s content.
In your case, when content control have multiple lines, you have to iterate all it’s child Run nodes (in case of textual content) and calculate their rectangles and then calculate sum of all these rectangles to get the final rectangle.
Also, in your case SDT spans several pages so it cannot be considered as a single element from point of document layout view.
Based on your advice, I spent some time experimenting with different combinations of MoveParent, MovePreviousLogical, MoveFirstChild etc of the LayoutEnumerator. I’m not sure if I’m doing anything wrong, but it looks like the information provided by LayoutEnumerator is not in line with what I see in Microsoft Word. I’m attaching the sample doc containing only one SDT that starts at the bottom of page 1 and continues on page 2.
My idea was:
Get the SDT handle. This works.
Iterate through all its child paragraphs. This works too. There is only one para in the SDT.
For each para, call collector.GetEntity(para). This works and gives me the last character (which is a paragraph break).
Call MoveParent() to get the Line object. This works too.
Call MovePrevious() in a loop till we get to the first line on the current page and get the cumulative sum of all lines to compute the height of SDT. This doesn’t work.
Somehow LayoutEnumerator thinks that the SDT lives on page 2 entirely. MovePrevious() call keeps working till it gets to the first line of the SDT which it thinks is the first line of page 2 as well.
Can you please help me understand what’s going on? A sample function that could help me compute the total height of a multi-line/multi-page SDT would be very kind of you.
aah… i just realized what’s happening. it is the library injecting the evaluation copy notice in the output document that pushes my SDT further down to page 2. A bit of annoyance, isn’t it? My humble suggestion is to use some alternate way of injecting copyright notice because the current method obstructs developer’s experimentation with LayoutEnumerator.
@Shujee Since you cannot use LayoutCollector.GetEntity method with Run nodes, you can work this around using bookmarks. I have created a simple code example that demonstrates the technique. In the code I split Run nodes into smaller parts and insert bookmarks. Then move LayoutEnumerator to bookmarks and calculate the rectangle occuped by structured document tag on both pages:
Document doc = new Document(@"C:\Temp\in.docx");
DocumentBuilder builder = new DocumentBuilder(doc);
NodeCollection sdts = doc.GetChildNodes(NodeType.StructuredDocumentTag, true);
foreach (StructuredDocumentTag tag in sdts)
{
List<Run> originalRuns = tag.GetChildNodes(NodeType.Run, true).Cast<Run>().ToList();
// Split Runs to smaller parts and put bookmarks to make it possible to navigate to each run.
int bookmakrIndex = 0;
foreach (Run r in originalRuns)
{
Run currentRun = r;
while (currentRun.Text.Length > 1 && currentRun.Text.IndexOf(' ', 1) > 0)
{
Node refNode = currentRun;
currentRun = SplitRun(currentRun, currentRun.Text.IndexOf(' ', 1));
refNode.ParentNode.InsertAfter(currentRun, refNode);
builder.MoveTo(currentRun);
string bkName = string.Format("tmp_bk_{0}", bookmakrIndex++);
builder.StartBookmark(bkName);
builder.EndBookmark(bkName);
}
}
}
// Node once we split Runs into smaller parts we can calculate rectangle occuped by SDT
LayoutCollector collector = new LayoutCollector(doc);
LayoutEnumerator enumerator = new LayoutEnumerator(doc);
foreach (StructuredDocumentTag tag in sdts)
{
RectangleF currentRect = new RectangleF();
int currentPage = collector.GetStartPageIndex(tag);
foreach (Bookmark b in tag.Range.Bookmarks)
{
enumerator.Current = collector.GetEntity(b.BookmarkEnd);
while (enumerator.Text == null || string.IsNullOrEmpty(enumerator.Text.Trim()))
{
if (!enumerator.MoveNext())
{
enumerator.MoveParent();
break;
}
}
if (enumerator.PageIndex != currentPage)
{
Console.WriteLine("{0} - {1}", currentPage, currentRect);
currentPage = enumerator.PageIndex;
currentRect = new RectangleF();
}
currentRect = currentRect.IsEmpty ? enumerator.Rectangle : RectangleF.Union(currentRect, enumerator.Rectangle);
}
Console.WriteLine("{0} - {1}", currentPage, currentRect);
// Remove temporaty boormarks.
tag.Range.Bookmarks.Clear();
}
doc.Save(@"C:\Temp\out.docx");
Sets consent for sending user data to Google for online advertising purposes.
Sets consent for personalized advertising.
Cookie Notice
To provide you with the best experience, we use cookies for personalization, analytics, and ads. By using our site, you agree to our cookie policy.
More info
Enables storage, such as cookies, related to analytics.
Enables storage, such as cookies, related to advertising.
Sets consent for sending user data to Google for online advertising purposes.
Sets consent for personalized advertising.
Cookie Notice
To provide you with the best experience, we use cookies for personalization, analytics, and ads. By using our site, you agree to our cookie policy.
More info
Enables storage, such as cookies, related to analytics.
Enables storage, such as cookies, related to advertising.
Sets consent for sending user data to Google for online advertising purposes.