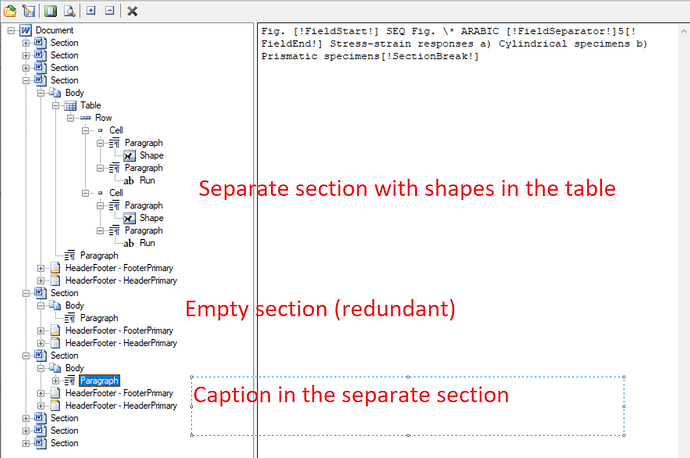
Dear team,
We are using image extraction using aspose java but some documents having chart file how to extract chart files using aspose please find below source code and document for your referance
if ((paragraph.toString(SaveFormat.TEXT).toLowerCase().trim().startsWith("fig")
|| paragraph.toString(SaveFormat.TEXT).startsWith("Scheme")
|| paragraph.toString(SaveFormat.TEXT).startsWith("Plate")
|| paragraph.toString(SaveFormat.TEXT).startsWith("Abb")
|| paragraph.toString(SaveFormat.TEXT).startsWith("Abbildung"))
// for duplicate figure caption it-15
&& (paragraph.getNextSibling() != null
&& !paragraph.getNextSibling().toString(SaveFormat.TEXT).trim().matches(matches)
|| (paragraph.getNextSibling() != null
&& paragraph.getNextSibling().getNodeType() != NodeType.TABLE
&& paragraph.getNextSibling().toString(SaveFormat.TEXT).trim().matches(matches)
&& (((Paragraph) paragraph.getNextSibling()).getChildNodes(NodeType.SHAPE, true)
.getCount() > 0
|| (paragraph.getNextSibling().getNextSibling()) != null
&& paragraph.getNextSibling().getNextSibling()
.getNodeType() != NodeType.TABLE
&& ((((Paragraph) paragraph.getNextSibling().getNextSibling())
.getChildNodes(NodeType.SHAPE, true).getCount() == 0)
//this codition added by pavi-14-12-2021 for duplicate captions
||(((Paragraph) paragraph.getNextSibling().getNextSibling())
.getChildNodes(NodeType.SHAPE, true).getCount() > 0))))
|| paragraph.getParentSection().getBody().getLastParagraph().getText().trim()
.matches(matches))
// for duplicate figure caption
&& ((paragraph.getPreviousSibling() != null
&& paragraph.getPreviousSibling().getNodeType() != NodeType.TABLE)
|| paragraph.getParentSection().getBody().getFirstParagraph().getText().trim()
.matches(matches))
&& paragraph.getNodeType() != NodeType.TABLE
&& paragraph.getParentNode().getNodeType() != NodeType.CELL
&& !paragraph.toString(SaveFormat.TEXT).contains(AIE.docName)
//condition added by pavi -14-12-2021
&& (!(paragraph.toString(SaveFormat.TEXT).trim().startsWith("Figure Captions"))||
!(paragraph.toString(SaveFormat.TEXT).trim().startsWith("Figures")))
|| ((paragraph.getNextSibling() == null) && (builder.getCurrentParagraph().isEndOfDocument())))
{
input : revised manuscript clean version.DOCX (1.4 MB)