Hi,
We realised that when converting certain Arabic characters, Aspose is puting some accent to the wrong place.
If you test the Word document I provided, you will noticed that the character U+064B : ARABIC FATHATAN is misplaced. We also noticed the issue with the character U+064E ARABIC FATHA and U+0651 ARABIC SHADDA.
We could try to come up with some sort of logic to fix those, but it would be best if Aspose got it right in the first place.
Thanks
brokenAspose.zip (6.2 KB)
@gvlicenseit
It appears you are encountering issues with the placement of diacritics in Arabic characters when converting a Word document to PDF using Aspose.Words. This problem can arise due to the complexities involved in rendering Arabic script, which relies on contextual shaping.
To resolve this issue, please ensure that you are using the latest version of Aspose.Words, as updates often include important fixes for rendering problems. Additionally, consider experimenting with different rendering options or fonts that are known to provide better support for Arabic characters.
If the issue continues, please provide the specific version of Aspose.Words you are using along with any relevant code snippets. This information will assist in diagnosing the problem more effectively.
For further assistance, you may want to explore the Aspose documentation or community forums for similar issues and potential solutions.
I’ve tried even with the latest version, from this link: Convert DOC To PDF C++
@gvlicenseit To get the output closer to MS Word it is required to enable open type features. Aspose.Words.Shaping.Harfbuzz package provides support for OpenType features in Aspose.Words using the HarfBuzz text shaping engine. You should enabling open type features to get the expected result. To achieve this you should add reference to Aspose.Words Shaping Harfbuzz plugin and use the following code to convert your document:
Document doc = new Document(@"C:\Temp\in.doc");
doc.LayoutOptions.TextShaperFactory = Aspose.Words.Shaping.HarfBuzz.HarfBuzzTextShaperFactory.Instance;
doc.Save(@"C:\Temp\out_HarfBuzz.pdf");
out.pdf (15.9 KB)
Amazing, many thanks!
Can I always have that enabled or should I just enable it with file using Arabic language?
Another question, we’re using Aspose.Words in c++, but I can’t seem to find the equivalent function to enable OpenType features in c++, is it not available there @alexey.noskov ?
I’ve actually found it!
https://www.nuget.org/packages/Aspose.Words.Shaping.HarfBuzz.Cpp
It was just missing from the c++ documentation
@gvlicenseit It is perfect that you managed to achieve what you need. Please feel free to ask in case of any further issues. We are always glad to help you.
There should not be any harm in having open type features always enabled.
1 Like
Thanks a lot @alexey.noskov .
Now that I have analyze the file, I’ve realized that it’s adding a lot of extra spaces when converting from doc to pdf.
We’re going from علًاجًا مطولًا to ع لًا ل جا مطو لًا
1 space character → 5 space characters.
If I disable the HarfBuzz shaping, we’re going back to a single space character.
Any advice on how to fix this issue?
@gvlicenseit As I can see the document rendered with HarfBuzz looks the same as in MS Word. If it does not, please attach your problematic input and output documents here for our reference. We will check them and provide you more information.
Thanks for the reply @alexey.noskov .
Even though they do look similar, Aspose is not recreating the 2 words properly, if you copy the whole text from the generated PDF in something like What Unicode character is this ? you can see that 4 space characters have been added, which results in differences in meaning when copying from the generated character.
Please find 2 PDFs attached, the generated.pdf is the one I get from Aspose, and the expected.pdf is what I would expect from it.
expected.pdf (85.1 KB)
generated.pdf (15.9 KB)
@gvlicenseit
We have opened the following new ticket(s) in our internal issue tracking system and will deliver their fixes according to the terms mentioned in Free Support Policies.
Issue ID(s): WORDSNET-28684
You can obtain Paid Support Services if you need support on a priority basis, along with the direct access to our Paid Support management team.
Thank you!
EDIT: My initial assumption about Span container is wrong, it does NOT fix the issue, sorry.
Initial assumption:
If that helps, the issue seems to be coming from the fact that, after the Aspose processing, the structure of the PDF is as follow (one “Span” container per letter):
But if I modify it manually, and put all the TextElement of a word within a single Span container, I’m getting the proper result. As such:
I hope this helps!
@gvlicenseit Thank you for additional information. We will keep you updated and let you know once the problem is resolved or we have more information for you.
@gvlicenseit Here is feedback from our development team:
As far as we understand the issue is an extra space and a mismatched LAM glyph when the text is copied from Aspose.Words PDF output to somewhere else.
You have mentioned https://www.babelstone.co.uk/Unicode/whatisit.html tool used to verify the glyphs.
It appears that if the same operation is done with MS Word pdf output provided by the submitter or Aspose PDF Maker output provided by you in the forum, the result is even worse (more extra spaces, and the result is visibly more different).
So we assume that you expect that copy-pasting from Aspose.Words pdf output matches copy-pasting from MS Word editor (even though copy-pasting from MS Word pdf output does not match it). Please confirm.
Thanks @alexey.noskov .
There seems to be some difference with the results I’m getting.
I’m going to redo everything as your dev team did, as I don’t think we’re getting the same results at all.
Word document text: علًاجًا مطولًا
Output from https://www.babelstone.co.uk/Unicode/whatisit.html:
PDF generated from word, using this option:
give this text: علًا جًا مطولًا
Output from
https://www.babelstone.co.uk/Unicode/whatisit.html:
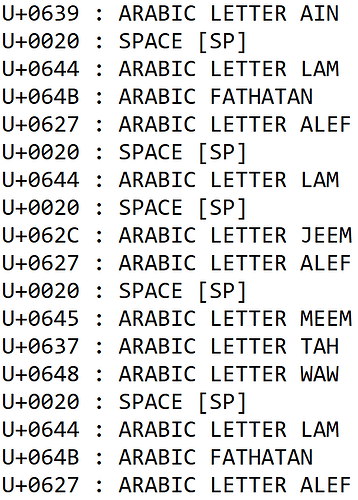
PDF generated by AW text: ع لًا ل جا مطو لًا
Output from https://www.babelstone.co.uk/Unicode/whatisit.html:
The expected.pdf was create in Acrobat by copying the text from Word doc directly and give exactly the same results as the Word document, only a single space.
For the Aspose results, I’m getting 4 extra spaces on top of the one already in there. Did they use any specific settings?
Here is the code used:
initLicense<Aspose::Words::License>();
auto doc = System::MakeObject<Aspose::Words::Document>(System::String(inputFilePath.c_str()));
auto folderFontSource = System::MakeObject<Aspose::Words::Fonts::FolderFontSource>(System::String(FONTS_DIR), false, 1);
doc->set_FontSettings(System::MakeObject<Aspose::Words::Fonts::FontSettings>());
doc->get_FontSettings()->SetFontsSources(System::MakeArray<System::SharedPtr<Aspose::Words::Fonts::FontSourceBase>>({folderFontSource}));
// accept all revisions in the document to remove them
doc->AcceptAllRevisions();
doc->GetChildNodes(Aspose::Words::NodeType::Comment, true)->Clear();
// When the text shaper factory is set, the layout starts to use OpenType features.
// An Instance property returns static BasicTextShaperCache object wrapping HarfBuzzTextShaperFactory
if (auto layoutOptions = doc->get_LayoutOptions())
{
layoutOptions->set_TextShaperFactory(Aspose::Words::Shaping::HarfBuzz::HarfBuzzTextShaperFactory::get_Instance());
}
if (removeHeadersFooters)
{
auto sections = doc->get_Sections();
const int sectionsCount = sections->get_Count();
for (int sectionIndex = 0; sectionIndex < sectionsCount; sectionIndex++)
{
if (auto section = sections->idx_get(sectionIndex))
{
section->ClearHeadersFooters();
}
}
}
doc->Save(System::String(outputFilePath.c_str()));
Thank you
@gvlicenseit Thank you for additional information. I forwarded it to the development team.
Hello @alexey.noskov
Any update on your end?
@gvlicenseit Unfortunately, there are no news yet regarding the issue. We will keep you updated and let you know once it is resolved or we have more information for you.
1 Like