word source code:
test.java.zip (500 Bytes)
origin html:
18c37f9d04c062d4ac713c64bfd8e197.html.zip (331.9 KB)
before converted:
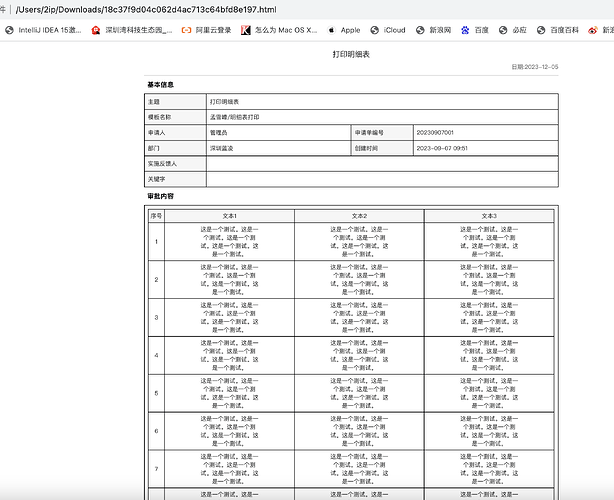
after converted:

It could not be viewed exactly,please have a check.
word source code:
test.java.zip (500 Bytes)
origin html:
18c37f9d04c062d4ac713c64bfd8e197.html.zip (331.9 KB)
before converted:
after converted:
It could not be viewed exactly,please have a check.
@hucq_landray_com_cn
We have opened the following new ticket(s) in our internal issue tracking system and will deliver their fixes according to the terms mentioned in Free Support Policies.
Issue ID(s): WORDSJAVA-2911
You can obtain Paid Support Services if you need support on a priority basis, along with the direct access to our Paid Support management team.
The issues you have found earlier (filed as WORDSJAVA-2911) have been fixed in this Aspose.Words for Java 23.12 update.
18c5706d670e48cbf6538364d32b6e88.html.zip (302.8 KB)
Still occured on another HTML,please hv a check.
@hucq_landray_com_cn Please note, Aspose.Words is designed to work with MS Word documents. HTML documents and MS Word documents object models are quite different and it is not always possible to provide 100% fidelity after conversion one format to another. In most cases Aspose.Words mimics MS Word behavior when work with HTML documents.
In your case the table is a little wider then page, so it is cut at the right size. You can use the following code to resolve the issue:
Document doc = new Document("C:\\Temp\\in.html");
for (Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
t.autoFit(AutoFitBehavior.AUTO_FIT_TO_WINDOW);
doc.save("C:\\Temp\\out.pdf");
Ok,thank you.
Document doc = new Document("/Users/2ip/Downloads/18c5bdeab239f5b8c92102d4d85bff49.html");
for (Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
t.autoFit(AutoFitBehavior.AUTO_FIT_TO_WINDOW);
doc.save("/Users/2ip/Downloads/out9.pdf",SaveFormat.PDF);
It’s ok by these codes.
FileInputStream f = new FileInputStream("/Users/2ip/Downloads/18c5bdeab239f5b8c92102d4d85bff49.html");
byte[] b = IOUtils.toByteArray(f);
String html = new String(b, "UTF-8");
Document doc = new Document();
DocumentBuilder builder = new DocumentBuilder(doc);
builder.insertHtml(html);
for (Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
t.autoFit(AutoFitBehavior.AUTO_FIT_TO_WINDOW);
doc.save("/Users/2ip/Downloads/out9.pdf", SaveFormat.PDF);
commons-compress-1.9.jar.zip (333.6 KB)
It’s not ok by these codes.
Would u tell me how to solve it by the second codes, because I should use inputstream.
@hucq_landray_com_cn It is not required to use DocumentBuilder to load an HTML document from input stream. You can use the following code:
FileInputStream f = new FileInputStream("/Users/2ip/Downloads/18c5bdeab239f5b8c92102d4d85bff49.html");
Document doc = new Document(f);
for (Table t : (Iterable<Table>)doc.getChildNodes(NodeType.TABLE, true))
t.autoFit(AutoFitBehavior.AUTO_FIT_TO_WINDOW);
doc.save("/Users/2ip/Downloads/out9.pdf", SaveFormat.PDF);
Ok,thank you again!
