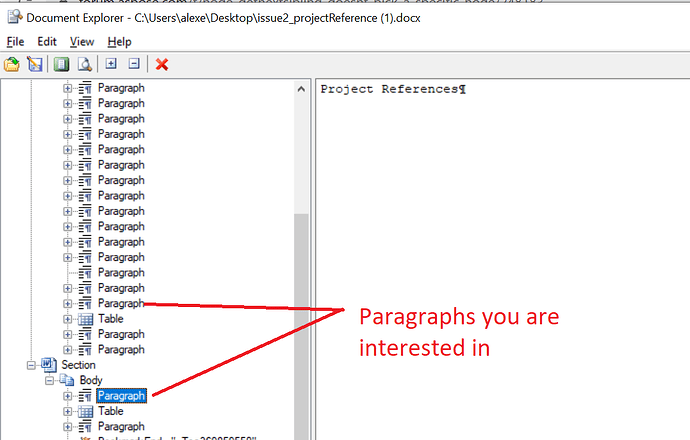
while traversing document using node.getNextSibling() method from a node, it doesn’t pick some nodes. code snippet and doc file attached.
build environment - Java 1.8, aspose-words - 20.8
code snippet :
public void issue2(String wordFileLocation) {
try {
Document doc = new Document(wordFileLocation);
NodeCollection paragraphs = doc.getChildNodes(NodeType.PARAGRAPH, true);
Node node = null;
for (Paragraph paragraph : (Iterable<Paragraph>) paragraphs) {
if (StringUtils.isNotEmpty(paragraph.getText()) && paragraph.getText().trim().equalsIgnoreCase("References")) {
node = paragraph;
break;
}
}
while (null != node) {
if (node.getText().trim().equalsIgnoreCase("System Life Cycle Procedures (SOPs & WPs)"))
System.out.println("-- found System Life Cycle Procedures (SOPs & WPs)");
if (node.getText().trim().equalsIgnoreCase("Project References"))
System.out.println("-- found Project References");
node = node.getNextSibling();
}
} catch (Exception e) {
e.printStackTrace();
}
}
Doc file used : issue2_projectReference.docx (42.5 KB)
Expected Output:
-- found System Life Cycle Procedures (SOPs & WPs)
-- found Project References
Actual Output:
-- found System Life Cycle Procedures (SOPs & WPs)