Hi Team,
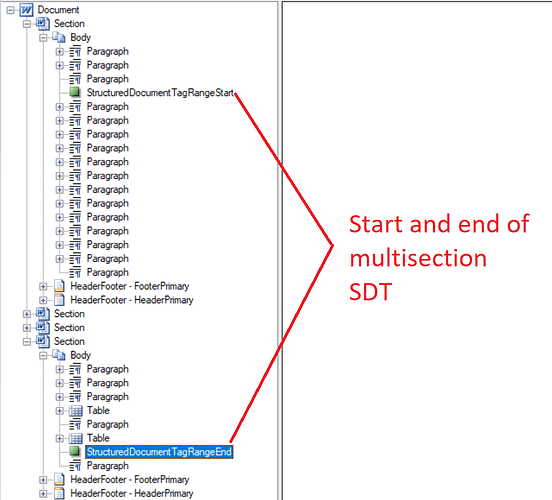
I have 2 documents , one with page break and other without page break. I am able to extract rich text content control from document without page break.I am using the following code base :
public static void main(String... args) throws Exception {
com.aspose.words.License license = new com.aspose.words.License();
license.setLicense("/home/saurabharora/aspose-licence.xml");
Document document = new Document("/home/saurabharora/Downloads/Schedule 3 Without page break.docx");
for (Object st : document.getChildNodes(NodeType.STRUCTURED_DOCUMENT_TAG, true)) {
StructuredDocumentTag std = (StructuredDocumentTag) st;
if ((std.getSdtType() == SdtType.RICH_TEXT)) {
System.out.println(std.getTag());
System.out.println(std.getTitle());
System.out.println(std.getText());
}
}
}
…
I get the following output for document without page break :
BASIC__1001__25425__138__138
Schedule
For and on behalf ofProvider Legal Entity (Recipient)aa Name: Provider Legal Entity Signatory: aa Title: Provider Legal Entity Signatory Title: aa Date of Signature: [ ] aa
..............
For other document (with page break), there is no output.
Attaching document for your reference.
Schedule 3.zip (36.3 KB)
Please help .