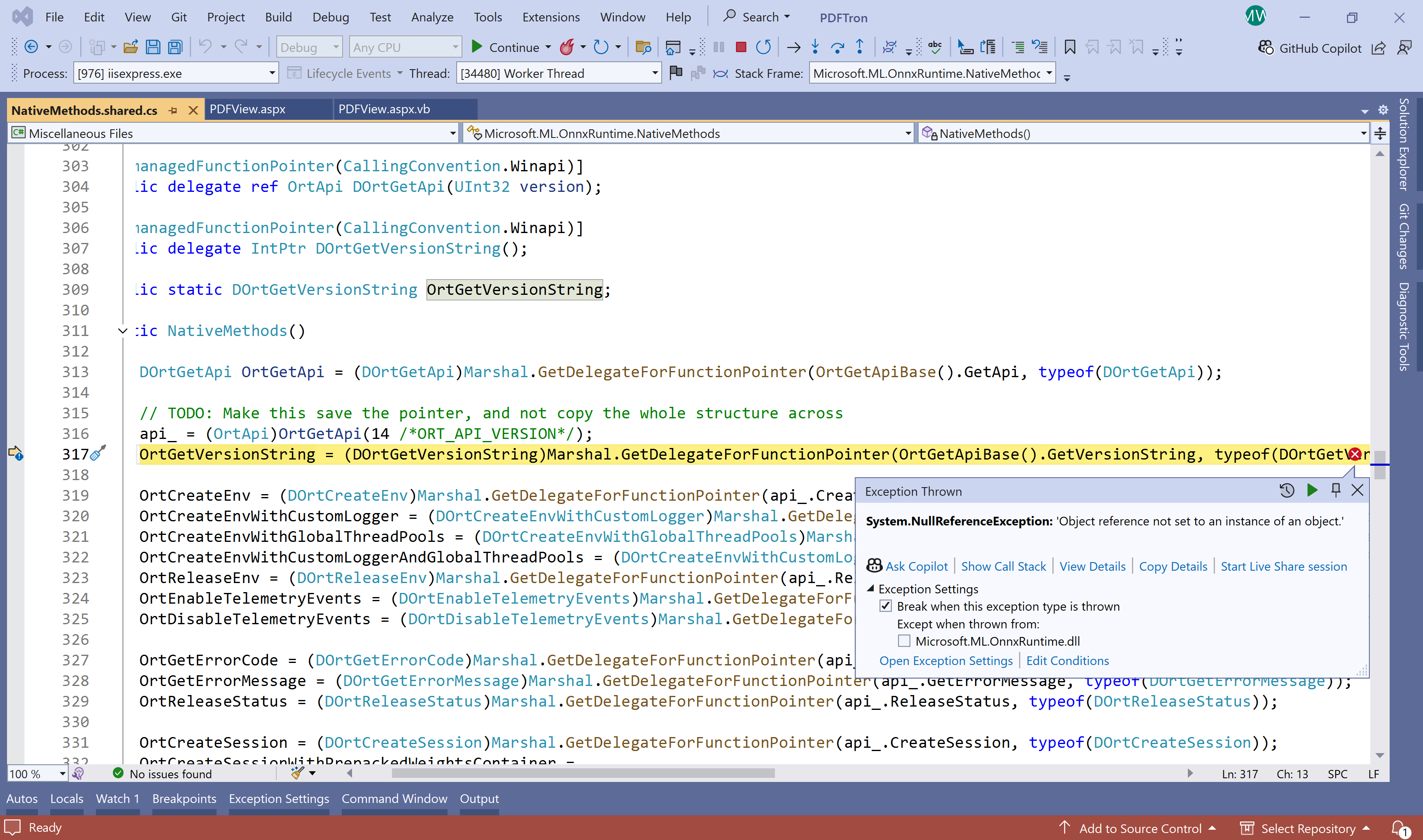
It errors out at the result = api.Recognize(PDF) line, saying “Object reference not set to an instance of an object”. It runs like it is trying to recognize the pdf file for about 30 seconds or more. Then that error.
The license code errors out at 'License.SetLicense(“Aspose.OCR.lic”) saying it cannot find license. It runs without those lines of code, I am not sure if this matters. It then errors out at the more crucial error above. The
The license file name is: Aspose.OCRfor.NET.lic, see license below function. I tried putting the .lic file in the website root directory, I tried both names, yours and the file name. It just cannot find the license. Please note I do not need these two lines for the pdf api. I have both the pdf and ocr dll’s referenced in my website.
Sub testOCR()
'Apply license
'Dim License As Aspose.OCR.License = New Aspose.OCR.License()
'License.SetLicense("Aspose.OCR.lic")
' Load the scanned PDF
Dim PDF As OcrInput = New OcrInput(InputType.PDF)
Dim pdfPath As String = AppDomain.CurrentDomain.BaseDirectory & "\pcuh.pdf"
Dim resultPath As String = AppDomain.CurrentDomain.BaseDirectory & "\pcuhSaved.pdf"
PDF.Add(pdfPath)
' Recognize the text from document
Dim api As AsposeOcr = New AsposeOcr()
Dim result As New List(Of RecognitionResult)
result = api.Recognize(PDF)
' Save searchable PDF
AsposeOcr.SaveMultipageDocument(resultPath, Aspose.OCR.SaveFormat.Pdf, result)
Stop
' Report progress
'Console.WriteLine($@"Recognition finished. See '{Directory.GetCurrentDirectory()}\Readable-Contract.pdf'.");
End Sub
It seems you are encountering two issues while using the Aspose.OCR library for processing a PDF file. Let’s address them one by one.
1. “Object reference not set to an instance of an object” Error
This error typically indicates that there is a null reference in your code. Here are a few steps to troubleshoot this issue:
Check PDF Path: Ensure that the path to the PDF file (pdfPath) is correct and that the file exists at that location. You can add a check to see if the file exists before attempting to add it to the OcrInput object.
Initialization of OcrInput: Make sure that the OcrInput object is properly initialized. You are using OcrInput(InputType.PDF), which is correct, but ensure that the PDF file is compatible with the OCR process.
Review Recognition Settings: If you are using any specific recognition settings, ensure they are correctly configured. You might want to try using default settings to see if that resolves the issue.
Here’s a modified version of your code with a check for the PDF file:
Sub testOCR()
' Apply license (if needed)
' Dim License As Aspose.OCR.License = New Aspose.OCR.License()
' License.SetLicense("Aspose.OCR.lic")
' Load the scanned PDF
Dim PDF As OcrInput = New OcrInput(InputType.PDF)
Dim pdfPath As String = AppDomain.CurrentDomain.BaseDirectory & "\pcuh.pdf"
Dim resultPath As String = AppDomain.CurrentDomain.BaseDirectory & "\pcuhSaved.pdf"
' Check if the PDF file exists
If Not System.IO.File.Exists(pdfPath) Then
Console.WriteLine("PDF file not found: " & pdfPath)
Return
End If
PDF.Add(pdfPath)
' Recognize the text from document
Dim api As AsposeOcr = New AsposeOcr()
Dim result As New List(Of RecognitionResult)
Try
result = api.Recognize(PDF)
' Save searchable PDF
AsposeOcr.SaveMultipageDocument(resultPath, Aspose.OCR.SaveFormat.Pdf, result)
Console.WriteLine("Recognition finished. See '" & resultPath & "'.")
Catch ex As Exception
Console.WriteLine("Error during recognition: " & ex.Message)
End Try
End Sub
2. License File Not Found
Regarding the license file issue, ensure that the license file is correctly placed in your project. Here are some tips:
File Location: The license file should be in the root directory of your application or in a path that your application can access. You can also specify the full path to the license file in the SetLicense method.
File Name: Make sure that the file name you are using in the SetLicense method matches exactly with the actual file name, including the extension.
Check for Exceptions: If the license file is not found, it may throw an exception. You can wrap the license setting code in a try-catch block to handle any potential errors.
Here’s how you can modify the license setting code:
Try
Dim License As Aspose.OCR.License = New Aspose.OCR.License()
License.SetLicense("Aspose.OCRfor.NET.lic") ' Ensure the name matches the actual file
Catch ex As Exception
Console.WriteLine("License error: " & ex.Message)
End Try
By following these steps, you should be able to resolve the issues you are facing with the OCR processing of your PDF file. If the problem persists, consider checking the Aspose documentation or community forums for further assistance.
Feel free to reach out if you have any more questions!
The pdf file exists. It throws the error in the below .cs file, on the line “result = api.Recognize(PDF)”. It seems to try and process for about 30 full seconds before it errors out. I cant recommend this api until I know it will read this pdf file.
Please see the pdf file attached. We need to turn this file, (page 2 specifically), into actual grids we can read from. As it is now the pdf is either scanned or flattened or something. It’s not real data. I am new to all this so I apologize for knowing too much about this. I am not new to system design and development, just ocr and pdf file manipulation. If the pef file is not suitable for some reason, please let me know. The client will be dealing with many pdf files.
We have removed your license information from you first post as it is recommended to share your license unless we specifically request for it via private message.
Furthermore, would you kindly confirm which version of the API are you using?
I just uninstalled the 24.8.0 using Nuget inside visual studio and installed 28.4.1. Still get the same error. Any assistance would be greatly appreciated.
Your initial post was about the above error you were facing? Are you saying that you are trying to use the latest version to check if error still persists and you are not able to use it because the error at setting license?
If so, your license must be older and its subscription must be expired. You can use the license only with the versions of the API that were released before its expiry date. You can however test the latest version with a 30-days free temporary license to check if the issue is related to older version of the API.
I am not setting the license, I am getting to the code where it goes bold. The pdf file exists all the code runs to this point. It just errors out after about 30 secinds with the error. I am pretty sure the license is not the issue. I uninstalled the version as I saw a newer version. I just need it to work. To use the ocr to make a readable pdf file I can then use the pdf.dll on.
For context I am not setting the license on the pdf.dll functions I made and it runs fine.
I really need to read these pdf files that are not really data. Thank you.
Dim PDF As OcrInput = New OcrInput(InputType.PDF)
Dim pdfPath As String = AppDomain.CurrentDomain.BaseDirectory & “pcuh.pdf”
Dim resultPath As String = AppDomain.CurrentDomain.BaseDirectory & “pcuhSaved.pdf”
PDF.Add(pdfPath)
’ Recognize the text from document
Dim api As AsposeOcr = New AsposeOcr()
Dim result As New List(Of RecognitionResult)
result = api.Recognize(PDF) <—–Errors her after 30 seconds
’ Save searchable PDF
AsposeOcr.SaveMultipageDocument(resultPath, Aspose.OCR.SaveFormat.Pdf, result)
The PDF file that you shared above does not have any scanned image but it has mixed content i.e. text and images. It is not some type of PDF you need to perform OCR operation on. You can extract text and read them using Aspose.PDF for .NET instead:
[C#]
Document pdfDocument = new Document(dataDir + "pcuh.pdf");
var tfa = new TextAbsorber();
pdfDocument.Pages.Accept(tfa);
var text = tfa.Text;
Aspose.OCR does not support processing of PDF files with mixed content. This functionality is still under consideration. However, below workaround can be used where you convert every page of the PDF into an image and then perform OCR on it using Aspose.OCR.
[C#]
string pdfPath = $"{dataDir}Kroll 2022 Annual Report.pdf";
List<Aspose.OCR.RecognitionResult> ocrResults = new List<Aspose.OCR.RecognitionResult>();
Aspose.OCR.AsposeOcr api = new Aspose.OCR.AsposeOcr();
// Resolution resolution = new Resolution(300);
// PngDevice imageDevice = new PngDevice(resolution);
PngDevice imageDevice = new PngDevice();
Document pdfDocument = new Document(pdfPath);
for (int pageCount = 1; pageCount <= pdfDocument.Pages.Count; pageCount++)
{
using (MemoryStream ms = new MemoryStream())
{
// Convert a particular page and save the image to stream
imageDevice.Process(pdfDocument.Pages[pageCount], ms);
Aspose.OCR.OcrInput input = new Aspose.OCR.OcrInput(Aspose.OCR.InputType.SingleImage);
input.Add(ms);
var recognResult = api.Recognize(input, new Aspose.OCR.RecognitionSettings { DetectAreasMode = Aspose.OCR.DetectAreasMode.TABLE });
ocrResults.Add(recognResult[0]);
ms.Close();
}
}
Aspose.OCR.AsposeOcr.SaveMultipageDocument(dataDir + "/res.txt", Aspose.OCR.SaveFormat.Text, ocrResults);
Ok in the example code you seem to be saving the results into a txt file? Would I not need to save it as an image file then save the image file to a pdf file?
The goal is to get any pdf file to an image file then convert it back to a pdf file so I can read any grid.
Hello, we are back where we started. Error: System.NullReferenceException: ‘Object reference not set to an instance of an object.’
On this line of code: Dim recognResult = api.Recognize(input, New RecognitionSettings With {.DetectAreasMode = DetectAreasMode.TABLE})
Same function call. Can you please tell me what variable is not set, I even made a new variable [recognResult ] and made sure it was dimensioned. So this is the same error and the same line of code as before.
I also made a new variable for
Dim rg As New Aspose.OCR.RecognitionSettings
rg.DetectAreasMode = DetectAreasMode.TABLE
Please note the licenses are there and working. It is not a license issue. The pdf file is there and working. It simply wont “recognize”. Ok thanks.
I have looked at every parameter and variable they seem to be instantiated. I am not sure about the [api] variable itself though. I cant see what I am missing.
Ok thank you for your help.
Function pdfToImage() As Boolean
Dim LicenseOCR As Aspose.OCR.License = New Aspose.OCR.License()
Dim LicensePDF As Aspose.Pdf.License = New Aspose.Pdf.License()
Dim licFileOCR As String = AppDomain.CurrentDomain.BaseDirectory & “Aspose.OCR.NET.lic”
Dim licFilePDF As String = AppDomain.CurrentDomain.BaseDirectory & “Aspose.PDF.NET.lic”
LicenseOCR.SetLicense(licFileOCR)
LicensePDF.SetLicense(licFilePDF)
Dim pdfPath As String = AppDomain.CurrentDomain.BaseDirectory & "pcuh.pdf"
Dim resultPath As String = AppDomain.CurrentDomain.BaseDirectory & "pcuhSaved.pdf"
'License.SetLicense("Aspose.OCR.lic")
Dim PdfDocument As Aspose.Pdf.Document = New Aspose.Pdf.Document(pdfPath)
Dim tfa As New TextAbsorber()
PdfDocument.Pages.Accept(tfa)
Dim Text As String = tfa.Text
Dim ocrResults As New List(Of RecognitionResult)()
Dim recognResult As New List(Of RecognitionResult)()
Dim api As New AsposeOcr()
Dim imageDevice As New PngDevice()
For pageCount As Integer = 1 To pdfDocument.Pages.Count
Using ms As New MemoryStream()
' Convert a particular page and save the image to the stream
imageDevice.Process(pdfDocument.Pages(pageCount), ms)
Dim input As New OcrInput(InputType.SingleImage)
input.Add(ms)
Dim rg As New Aspose.OCR.RecognitionSettings
rg.DetectAreasMode = DetectAreasMode.TABLE
recognResult = api.Recognize(input, rg)
'recognResult = api.Recognize(input, New RecognitionSettings With {.DetectAreasMode = DetectAreasMode.TABLE})
ocrResults.Add(recognResult(0))
End Using
Next
'AsposeOcr.SaveMultipageDocument(DATADIR & "/res.txt", SaveFormat.Text, ocrResults)
AsposeOcr.SaveMultipageDocument(resultPath, Aspose.OCR.SaveFormat.Text, ocrResults)
Return True
We are sorry for the trouble. We were not able to face any exception similar to what you shared. However, we noticed that the memory consumption was too high while using the code with both Aspose.PDF and Aspose.OCR APIs. If possible, could you please share a sample console application in .zip format with us which would allow us to test and replicate the same issue that you are facing?
So you were able to get this code to run with no errors? You need me to make a console application and call this function from there? Why? You need me to make a new application and paste this function into it?
I dont understand why you would need me to do that, but ok. I’ll do that now.
The zip file is too big, it wont let me upload it. This is not good. Does this ocr thing work or not? I am able to use the pdf.dll and would be happy to recommend it to my client. But if I cant read the pdf filers in their various formats, then I cannot recommend your products.
Please make a console aapp and from ther main function call this function:
I got this function to run b ut the resulting pdf was not able to be read. As you can see for the code the origina mixed file is pcuh.pdf the result file is savedPcuh.pdf. The saved file is not readable.
I just need to save the mixed file as an image and then make the image a real pdf with real grids on page 2. All I need is page 2 as pdf grids so I can import the data.
Why did this work in a console app but not the website? That is troubling, is it a memory issue?
Again the function finally worked nut the resulting file was not useable.
Function pdfToImage() As Boolean
Dim LicenseOCR As Aspose.OCR.License = New Aspose.OCR.License()
Dim LicensePDF As Aspose.Pdf.License = New Aspose.Pdf.License()
Dim licFileOCR As String = Environment.CurrentDirectory & “\Aspose.OCR.NET.lic”
Dim licFilePDF As String = Environment.CurrentDirectory & “\Aspose.PDF.NET.lic”
'Dim licFileOCR As String = AppDomain.CurrentDomain.BaseDirectory & “Aspose.OCR.NET.lic”
'Dim licFilePDF As String = AppDomain.CurrentDomain.BaseDirectory & “Aspose.PDF.NET.lic”
LicenseOCR.SetLicense(licFileOCR)
LicensePDF.SetLicense(licFilePDF)
Dim pdfPath As String = Environment.CurrentDirectory & "\pcuh.pdf"
Dim resultPath As String = Environment.CurrentDirectory & "\pcuhSaved.pdf"
'License.SetLicense("Aspose.OCR.lic")
Dim PdfDocument As Aspose.Pdf.Document = New Aspose.Pdf.Document(pdfPath)
Dim tfa As New TextAbsorber()
PdfDocument.Pages.Accept(tfa)
Dim Text As String = tfa.Text
Dim ocrResults As New List(Of RecognitionResult)()
Dim recognResult As New List(Of RecognitionResult)()
Dim api As New AsposeOcr()
Dim imageDevice As New PngDevice()
For pageCount As Integer = 1 To PdfDocument.Pages.Count
Console.WriteLine("Page: " & pageCount.ToString())
Using ms As New MemoryStream()
' Convert a particular page and save the image to the stream
imageDevice.Process(PdfDocument.Pages(pageCount), ms)
Dim input As New OcrInput(InputType.SingleImage)
input.Add(ms)
Dim rg As New Aspose.OCR.RecognitionSettings
rg.DetectAreasMode = DetectAreasMode.TABLE
Console.WriteLine("Begin Recognize Page: " & pageCount.ToString())
recognResult = api.Recognize(input, rg)
Console.WriteLine("End Recognize Page: " & pageCount.ToString())
'recognResult = api.Recognize(input, New RecognitionSettings With {.DetectAreasMode = DetectAreasMode.TABLE})
ocrResults.Add(recognResult(0))
Console.WriteLine("-------------------------")
End Using
Next
'AsposeOcr.SaveMultipageDocument(DATADIR & "/res.txt", SaveFormat.Text, ocrResults)
AsposeOcr.SaveMultipageDocument(resultPath, Aspose.OCR.SaveFormat.Text, ocrResults)
Console.WriteLine("End")
Return True
Here is the original mixed file, pcuh.pdf. Using the console I was able to make a pcuhSaved.pdf with all pages but it is too big to post here. So I made a single pdf file out of page 2 called pcuhSaved2.pdf. It is attached, can you please describe to me what I made.
There a no tables on page 2. So while I can see grids they are not grids. So I assume it is an image or something. So, how do I turn page 2 into a readable file with grids?
We apologize for the delayed response. The confusion is being caused due to the sample file you have shared with us. As shared in one of our previous responses, your sample PDF is already readable and can simply be processed to extract text using Aspose.PDF API. You don’t need Aspose.OCR to make it readable when its already readable.
Supposing that you may have some PDF files that have scanned images in some pages and readable text on some pages (mixed content), you can use both Aspose.PDF and Aspose.OCR to obtain an output PDF that will have scanned images with a layer of OCR’d text results (this is what your pcuhSaved.pdf file has at the moment).
Again we are not certain what do you actually mean by making the page 2 grids readable. Page 2 of the original file already has readable text in the grids. Do you mean you want to extract text in a way that you could determine the rows and columns values individually? OR do you expect to receive such PDFs with scanned images in which there could be grids and you need to determine each cells using Aspose.OCR?
The PDF output that you shared and what we obtained using Aspose.OCR contains garbage characters. Looks like the API is not able to read the data from a scanned image with this resolution and font size. We will be proceeding further with logging the tasks and issues in our issue management system once you please provide your feedback against our above questions and assumptions.
We tried reading these grids in another api last month and it was not able to. I was told by aspose that this pdf file was both text and images. So I assumed the grids were images. I see that is not the case.
Is there any reason we cannot use the ocr.dll in a website and have to use it in a console application? Is there a work around?