文档:
电风扇.docx (31.0 KB)
请问上述文档中的表格样式怎么调整为适应文档宽度?
@ouchli 该文档具有兼容模式和版本 11,这意味着它与 Word 2003 的兼容性最好。您可以使用 doc.getCompatibilityOptions().optimizeFor(MsWordVersion.WORD_2003); 转换此文档或将其转换为最新版本。下面是转换后的文档:
updated.docx (33.7 KB)
请问怎么将这份文档使用aspose转换为最新版本的文档,还有您是怎么判断到这份文档与Word 2003的兼容性最好?
@ouchli 如果解压 docx 文件,可以打开 settings.xml 并找到 <w:compatSetting w:name=“compatibilityMode” w:uri=“http://schemas.microsoft.com/office/word” w:val=“11”/>。您可以通过以下链接 WdCompatibilityMode enumeration (Word) | Microsoft Learn 查看这个值 11。不过,经过进一步分析,我发现造成这种行为的原因是该文件中启用了一个选项“Allow Tables to AutoFit Into Page Margins”。通过doc.getCompatibilityOptions().setGrowAutofit(false);禁用该选项后,表格显示正确。当我们使用doc.getCompatibilityOptions().optimizeFor(MsWordVersion.WORD_2003);或其他版本时,默认情况下该选项将被禁用,因此我认为没有必要将文档优化到某些版本,但要确保该选项已被禁用。
您好,我的问题如下:
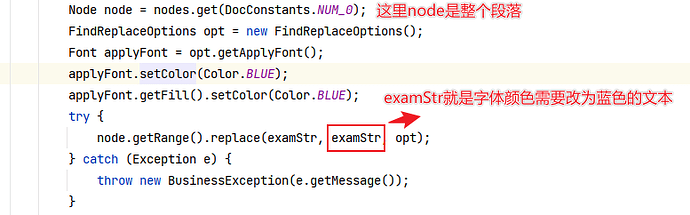
我的文档中有一段文本是这样的,如下图,<>中原本内容是表2.1,我将其中的文字表2.1换成了表1,但是我保留了修订内容,这样我用代码para.toString(SaveFormat.TEXT)获取到的文本内容就是<表2.1表1>
那么现在当我想使用代码将<表1>文本的字体颜色改为蓝色,我使用的方法是通过文本替换的方式来改字体颜色,代码如下
您可以看到我最终得到的结果是这样的,不仅修订格式没了,且原本被删除了表2.1也显示出来了
所以基于以上描述,请问我如何避免这样的情况:我只需要修改被修订的内容的颜色,其余内容保持不变(包括修订样式及已删除内容)
@ouchli 遗憾的是,我无法用下面的简单代码重现这个问题:
Document doc = new Document(getMyDir() + "Revis.docx");
FindReplaceOptions options = new FindReplaceOptions();
Font font = options.getApplyFont();
font.getFill().setColor(Color.GREEN);
doc.getRange().replace("<Table 1>", "<Table 1>", options);
doc.save(getArtifactsDir() + "output.docx");
或者您可以使用
Document doc = new Document(getMyDir() + "Revis.docx");
NodeCollection runs = doc.getChildNodes(NodeType.RUN, true);
for (Run run : (Iterable<Run>) runs) {
if (run.getText().equals("<Table 1>")){
run.getFont().setColor(Color.GREEN);
}
}
doc.save(getArtifactsDir() + "output.docx");
两者产生了相同的结果:
能否在此提供您的文件以供测试?
在您的代码示例中,我没有看到修订的内容是如何处理,我重新叙述一下我的问题背景,我需要修改的内容是经过修订后的,这意味着我用替换的方式就会把已删除的内容重新添加到文本中
test1.docx (20.8 KB)
您可以用这个文件测试
@ouchli 是的,我的内容也修改过了。我刚把修订版切换到最终版,看到颜色变了。这是我这边的结果文档,没有问题。也许你的代码中还有其他东西会导致这个问题?
output.docx (19.6 KB)
Here is my code:
Document doc = new Document("test1.docx");
FindReplaceOptions options = new FindReplaceOptions();
Font font = options.getApplyFont();
font.setColor(Color.BLUE);
font.getFill().setColor(Color.BLUE);
doc.getRange().replace("table 2.1", "table 2.1", options);
doc.save("output.docx");
您可能没理解我问的问题,我的问题是说:
我是修改<>中的内容颜色,但是这个里面的内容我是通过代码para.toString(SaveFormat.TEXT)获取到的,但这个获取时候会将修订内容一起获取,也就是说我们最终代码中获取到的内容是,那么最终替换后的代码就是doc.getRange().replace(“table1 table 2.1”, “table1 table 2.1”, options);
也就是说,其核心是无法避免已删除的内容
@ouchli 感谢您提供补充信息。获取具体文本的唯一方法是检查段落是否为插入修订版,或者运行是否为插入修订版。
for (Paragraph para : paras) {
for (Run run : para.getRuns()) {
if (run.isInsertRevision())
System.out.println(run.toString(SaveFormat.TEXT));
}
}
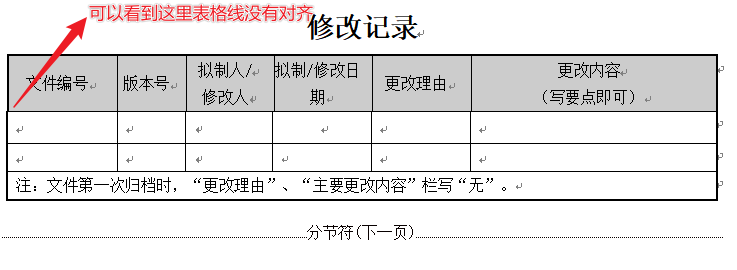
您好,请问文档中表格是这样的,他不是一个标准的表格

请问我该如何修改,使得他成为一个正常的表格呢,并且不会改变表格的内容
您可以看看我提供的附件
test.docx (40.6 KB)
这个有点着急,请及时回复一下,谢谢~
@ouchli 除了根据当前表格内容创建新表格外,很难对此类表格进行规范化处理。不过你可以试试下面的代码:
Document doc = new Document("test.docx");
Table table = (Table) doc.getChild(NodeType.TABLE, 0, true);
table.convertToHorizontallyMergedCells();
table.setAllowAutoFit(true);
if (table != null && table.getRows().getCount() > 0) {
for (Row row : table.getRows()) {
int i = 0;
for (Cell cell : row.getCells()) {
double firstRowCellWidth = table.getFirstRow().getCells().get(i).getCellFormat().getWidth();
double currCellWidth = cell.getCellFormat().getWidth();
if (firstRowCellWidth > currCellWidth) {
cell.getCellFormat().setWidth(firstRowCellWidth);
}
cell.getCellFormat().setPreferredWidth(PreferredWidth.AUTO);
i++;
}
}
}
doc.save("output.docx");
这和
Document doc = new Document("test.docx");
Table table = (Table) doc.getChild(NodeType.TABLE, 0, true);
table.convertToHorizontallyMergedCells();
table.setAllowAutoFit(true);
if (table != null && table.getRows().getCount() > 0) {
for (Row row : table.getRows()) {
int i = 0;
for (Cell cell : row.getCells()) {
double firstRowCellWidth = table.getFirstRow().getCells().get(i).getCellFormat().getWidth();
double currCellWidth = cell.getCellFormat().getWidth();
if (firstRowCellWidth > currCellWidth) {
cell.getCellFormat().setWidth(firstRowCellWidth);
}
i++;
}
}
}
doc.save("output.docx");
// Reload the document and adjust table auto-fit settings.
doc = new Document("output.docx");
table = (Table) doc.getChild(NodeType.TABLE, 0, true);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
doc.save("output.docx");
@ouchli 我设置了将第一行与其他行合并的宽度,但您的结果显示您没有在代码中使用cell.getCellFormat().setPreferredWidth(PreferredWidth.AUTO);,而这是需要的。该表有不同的合并单元格,其中一些单元格没有文本,这可能会在使用 table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS); 时产生问题。因此,有一种方法可以获得预期输出,即通过设置宽度对齐表格单元格,保存文档,然后将此表格与内容匹配。
Document doc = new Document("test.docx");
Table table = (Table) doc.getChild(NodeType.TABLE, 0, true);
if (table != null && table.getRows().getCount() > 0) {
for (Row row : table.getRows()) {
int i = 0;
for (Cell cell : row.getCells()) {
Cell firstRowCell = table.getFirstRow().getCells().get(i);
double firstRowCellWidth = firstRowCell.getCellFormat().getWidth();
double currCellWidth = cell.getCellFormat().getWidth();
if (firstRowCellWidth > currCellWidth) {
cell.getCellFormat().setWidth(firstRowCellWidth);
}
i++;
}
}
}
doc.save("output.docx");
// Reload the document and adjust table auto-fit settings.
doc = new Document(getArtifactsDir() + "output.docx");
table = (Table) doc.getChild(NodeType.TABLE, 0, true);
table.setAllowAutoFit(true);
for (Row row : table.getRows()) {
for (Cell cell : row.getCells()) {
cell.getCellFormat().setPreferredWidth(PreferredWidth.AUTO);
}
}
doc.save("output.docx");
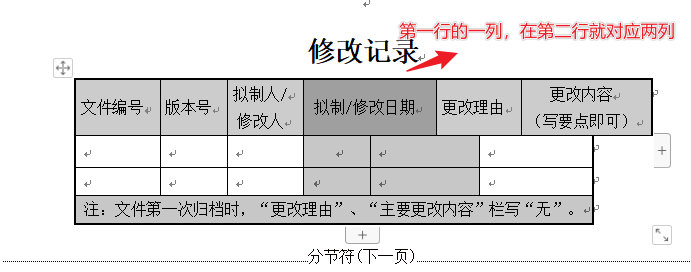
关于这个表格的问题,我有一个新的发现,,通过对该表格进行下图中的设置多次后,可得到规范的表格
具体过程可见下面这几张图
但是我用代码连续执行该设置后,得到的结果却不是我想要的,请问这是什么原因呢
Document doc = new Document("test.docx");
Table table = (Table) doc.getChild(NodeType.TABLE, 0, true);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
doc.save("output3.docx");
以下是原文档和执行代码后得到的文档
test.docx (40.5 KB)
output3.docx (40.4 KB)
@ouchli 它可以作为手动修复的变通方法。由于某些单元格中没有数据,表格计算和显示会出现错误。MS Word 和 WPS 一样可以即时更新计算,因此即使我们处理文档中的其他内容,它们也能固定表格。在这种情况下,经过进一步调查,我发现唯一的办法就是在使用这些表格时,固定第一行的单元格宽度并更新页面布局:
Document doc = new Document("test.docx");
Table table = (Table) doc.getChild(NodeType.TABLE, 0, true);
int i = 0;
for (Cell cell : table.getFirstRow().getCells()) {
Cell secondRowCell = table.getRows().get(1).getCells().get(i);
cell.getCellFormat().setWidth(secondRowCell.getCellFormat().getWidth());
i++;
}
doc.updatePageLayout();
table.autoFit(AutoFitBehavior.AUTO_FIT_TO_CONTENTS);
doc.updatePageLayout();
doc.save("output.docx");
你好,我有这样一个问题:
假设现在有一个节点 lastHyperLink是一篇文档的最后一个目录段落,startNode是这篇文档的第一个标题的段落,现在我要获取这两个节点之间所有的节点集合,
我使用的方法是以下代码
List<Node> nodes = new ArrayList<>();
Paragraph lastHyperLink = hyperLink.get(hyperLink.size() - DocConstants.NUM_1).getTocItemParagraph();
Node nextSibling = lastHyperLink.getNextSibling();
while (Objects.nonNull(nextSibling) && !nextSibling.equals(startNode)) {
// 若为段落,需要判断是否包含分页符(分页符不能删除)
if (NodeType.PARAGRAPH != startNode.getNodeType() || !((Paragraph)
nextSibling).getParagraphFormat().getPageBreakBefore()) {
nodes.add(nextSibling);
}
nextSibling = nextSibling.getNextSibling();
}
原文件是这样的,
我的问题是:为何lastHyperLink.getNextSibling().getNextSibling()得到的对象是null对象呢
@ouchli 没有档案很难说。你能把它放在这里做测试吗?
如果我们谈论两段,那么就会有一段接一段。如果我们尝试获取例如字段,然后当字段或另一个节点结束时,您可以获得null,则可能会发生这种情况。在这种情况下,您可以使用nextPreOrder。然而,我认为如果没有特殊情况,你可以收集段落节点,然后对它们做点什么。此外,您不需要获取最后一个超链接,因为文档中的TOC看起来像’TOC\o“1-3”\h\z\u’,所以您可以在此基础上获取段落。以下是一个示例:
Document doc = new Document("input.docx");
Paragraph tocPara = null;
for (Paragraph para : (Iterable<Paragraph>) doc.getChildNodes(NodeType.PARAGRAPH, true)) {
if (para.getRange().getText().contains("TOC")) {
tocPara = para;
break;
}
}
ArrayList<Node> nodes = new ArrayList<>();
Node nextSibling = tocPara.getNextSibling();
while (Objects.nonNull(nextSibling)) {
if (((Paragraph)nextSibling).getParagraphFormat().isHeading())
break;
if (!((Paragraph)nextSibling).getParagraphFormat().getPageBreakBefore()) {
nodes.add(nextSibling);
}
nextSibling = nextSibling.getNextSibling();
}
doc.save("output.docx");
你好,我有一个问题,我用如下代码来删除最后一个目录和第一个标题之间的段落(不包括分页符),并保持修订状态,为何最终文档中,接受修订后会把整个目录给删除,请帮忙看看,谢谢~
这里是原文档
test.docx (36.9 KB)
下面是我的代码
Document document = new Document("D:\\test.docx");
HeadingVo firstHeading = AsposeWordUtil.getFirstHeading(document);
Node startNode=firstHeading.getParagraph();
List<HyperLinkVo> hyperLink = DocumentStructUtil.getHyperLink(document);
Paragraph lastHyperLink = hyperLink.get(hyperLink.size() - DocConstants.NUM_1).getTocItemParagraph();
List<Node> nodes = new ArrayList<>();
// startNode是第一个标题段落, lastHyperLink是最后一个目录段落
Node nextSibling = lastHyperLink.getNextSibling();
// 这里的逻辑是找两个段落之间的节点,过滤分页符
while (Objects.nonNull(nextSibling) && !nextSibling.equals(startNode)) {
boolean flag = NodeType.PARAGRAPH != nextSibling.getNodeType() ||
(!nextSibling.getText().contains(ControlChar.PAGE_BREAK) && !((Paragraph) nextSibling).getParagraphFormat().getPageBreakBefore());
if (flag) {
nodes.add(nextSibling);
}
nextSibling = nextSibling.getNextSibling();
}
Node previousSibling = startNode.getPreviousSibling();
while (Objects.nonNull(previousSibling) && !previousSibling.equals(lastHyperLink)) {
boolean flag = NodeType.PARAGRAPH != previousSibling.getNodeType() ||
(!previousSibling.getText().contains(ControlChar.PAGE_BREAK) && !((Paragraph) previousSibling).getParagraphFormat().getPageBreakBefore());
if (flag && !nodes.contains(previousSibling)) {
nodes.add(previousSibling);
}
previousSibling = previousSibling.getPreviousSibling();
}
document.startTrackRevisions("修订", new Date());
if (!CollectionUtils.isEmpty(nodes)) {
nodes.forEach(Node::remove);
}
document.save("D:out.docx");
下面是输出的文档
out.docx (37.6 KB)
@ouchli 这是因为超链接后的文本是TOC段落的一部分。
要求此字段后必须有一个空段落。因此,我们可以在TOC之后添加新段落,或者只删除下一段中的游程。以下是一个简单的变体:
builder.moveTo(lastHyperLink);
builder.insertParagraph();
// startNode是第一个标题段落, lastHyperLink是最后一个目录段落
Node nextSibling = lastHyperLink.getNextSibling().getNextSibling();
// 这里的逻辑是找两个段落之间的节点,过滤分页符
while (Objects.nonNull(nextSibling) && !nextSibling.equals(startNode)) {
boolean flag = NodeType.PARAGRAPH != nextSibling.getNodeType() ||
(!nextSibling.getText().contains(ControlChar.PAGE_BREAK) && !((Paragraph) nextSibling).getParagraphFormat().getPageBreakBefore());
if (flag) {
nodes.add(nextSibling);
}
nextSibling = nextSibling.getNextSibling();
}
Node previousSibling = startNode.getPreviousSibling();
while (Objects.nonNull(previousSibling) && !previousSibling.equals(lastHyperLink.getNextSibling())) {
boolean flag = NodeType.PARAGRAPH != previousSibling.getNodeType() ||
(!previousSibling.getText().contains(ControlChar.PAGE_BREAK) && !((Paragraph) previousSibling).getParagraphFormat().getPageBreakBefore());
if (flag && !nodes.contains(previousSibling)) {
nodes.add(previousSibling);
}
previousSibling = previousSibling.getPreviousSibling();
}