使用的是aspose Java最新试用版。
word转epub没问题!但是打开是单篇没有目录页.word分章转epub能实现吗?
pdf转epub带目录效果的,转后文件很小,sigil打不开
使用的代码: Convert PDF file to other formats|Aspose.PDF for Java
转换文档:
body_4-4.pdf (2.2 MB)
使用的是aspose Java最新试用版。
word转epub没问题!但是打开是单篇没有目录页.word分章转epub能实现吗?
pdf转epub带目录效果的,转后文件很小,sigil打不开
@SalesDhorde 您提供了 Aspose.Pdf 的代码。您是在使用 Aspose.Pdf 还是 Aspose.Words 时遇到问题?如果您在使用 Aspose.Words 时遇到问题,请提供您试图转换为电子书的 docx 文件。我们将调查该问题并为您提供更多信息。
使用word跟pdf都测试过的,但是转换都有问题,现在需要确认的是
1.pdf转epub带目录效果的,转后文件很小,sigil无法打开预览问题。
body_4-4.pdf (2.2 MB)
2.Aspose.Words 能通过word转epub,但是不知道怎么分目录章节。能否提供示例代码
32025-女性和HIV临床实用问答(第2版).zip (6.2 MB)
@SalesDhorde Aspose.Words 可根据标题样式或页面为 EPub 文件创建 TOC。您的文档没有此类样式,因此没有创建 TOC。要定义分割标准,您需要使用 DocumentSplitCriteria。
Document doc = new Document("epub.docx");
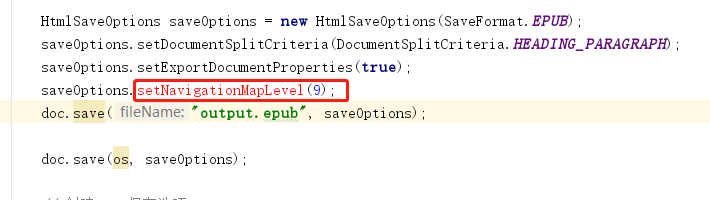
HtmlSaveOptions saveOptions = new HtmlSaveOptions(SaveFormat.EPUB);
saveOptions.setDocumentSplitCriteria(DocumentSplitCriteria.HEADING_PARAGRAPH);
saveOptions.setExportDocumentProperties(true);
saveOptions.setNavigationMapLevel(9);
doc.save("output.epub", saveOptions);
关于第一个问题,有什么解决办法吗?
@SalesDhorde 正如我在之前的评论中所说,Aspose。单词根据标题样式创建TOC。您当前的文档没有这样的样式。在使用转换之前,您需要为相应的段落设置标题样式。另一种方法是按页面创建TOC。为此,您可以使用“DocumentSplitCoderia.PAGE_BREAK”。请检查DocumentSplitCriteria | Aspose.Words for Java
怎么设置文档带上Heading 1样式或者转换有个目录页?
Aspose.word现在DocumentSplitCoderia.PAGE_BREAK是按页拆分,有没有什么办法我按页码范围拆分,我手动做过目录页加载到epub中
@SalesDhorde 在深入分析您的文档后,为段落设置任何样式都会破坏布局。这个 .docx 文件是手动创建的还是用任何程序创建的?
如果您想按页面范围分割文档,可以使用以下代码按章节分割页面:
Document doc = new Document("epub.docx");
ArrayList<Document> docs = extractDocumentPages(doc, 2);
Document newDoc = Merger.merge(docs.toArray(new Document[docs.size()]), MergeFormatMode.KEEP_SOURCE_FORMATTING);
newDoc.save("output.docx");
doc = new Document("output.docx");
HtmlSaveOptions saveOptions = new HtmlSaveOptions(SaveFormat.EPUB);
saveOptions.setDocumentSplitCriteria(DocumentSplitCriteria.SECTION_BREAK);
saveOptions.setExportDocumentProperties(true);
doc.save("output.epub", saveOptions);
public static ArrayList<Document> extractDocumentPages(Document sourceDoc, int pagesPerRange) throws Exception {
ArrayList<Document> extractedDocuments = new ArrayList<>();
int currentPageStart = 0;
int totalPageCount = sourceDoc.getPageCount();
while (currentPageStart < totalPageCount) {
int currentPageEnd = currentPageStart + pagesPerRange - 1;
if (currentPageEnd >= totalPageCount)
currentPageEnd = totalPageCount - 1;
// Extract pages from currentPageStart to currentPageEnd
Document extractedDoc = sourceDoc.extractPages(currentPageStart, currentPageEnd - currentPageStart + 1);
extractedDocuments.add(extractedDoc);
// Prepare for the next range
currentPageStart += pagesPerRange;
}
return extractedDocuments;
}