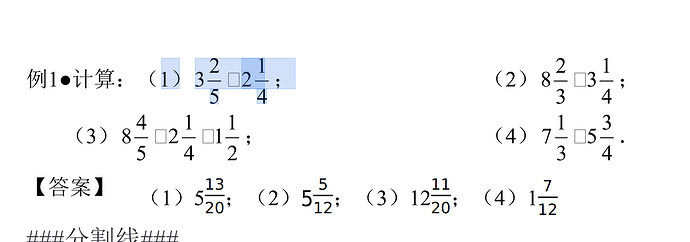word转pdf,图片里的公式被提取成文本,但符号变成了方块。
有什么办法可以禁止将图片里的内容提取成文本吗?
word:
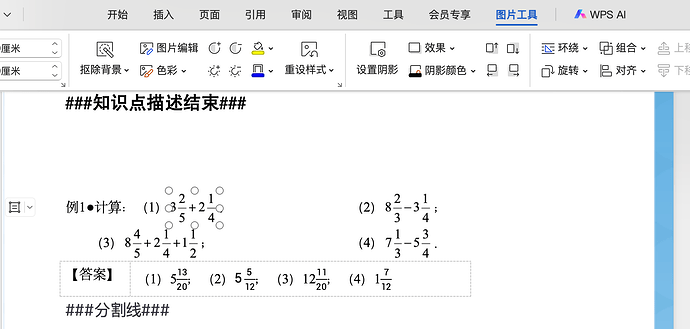
pdf:
apose.words版本是24.11
需求就是是否可以不识别word里图片的内容,直接按图片格式渲染为pdf。
@haibojiang 不幸的是,目前没有这样的选择。
我们已经在我们的内部问题跟踪系统中打开了以下新工单,并将根据 免费支持政策 中提到的条款提供它们的修复:
Issue ID(s): WORDSNET-28346
如果您需要优先支持以及直接联系我们的付费支持管理团队,您可以获得 付费支持服务 。
目前,作为一种解决方法,您可以在将文档导出为PDF之前将OfficeMath方程转换为图像。例如,请参阅以下代码:
Document doc = new Document("input.docx");
DocumentBuilder builder = new DocumentBuilder(doc);
for (OfficeMath m : (Iterable<OfficeMath>)doc.getChildNodes(NodeType.OFFICE_MATH, true))
{
// Process only top level OfficeMath.
if (m.getAncestor(NodeType.OFFICE_MATH) == null)
{
// Save office math as PNG.
ByteArrayOutputStream tmpStream = new ByteArrayOutputStream();
m.getMathRenderer().save(tmpStream, new ImageSaveOptions(SaveFormat.PNG));
builder.moveTo(m);
builder.insertImage(new ByteArrayInputStream(tmpStream.toByteArray()));
m.remove();
}
}
doc.save("output.pdf");
识别错误的不是OFFICE_MATH,而是Ole类型的node。
我尝试了以下代码,发现转出来的图片就已经符号是方块了。
Document document =new Document("input.docx");
NodeCollection shapes = document.getChildNodes(NodeType.SHAPE, true);
for (Node node : shapes.toArray()) {
Shape shape = (Shape) node;
if (shape.getOleFormat() != null && shape.getOleFormat().getProgId().contains("Equation")) {
// 将 OLE 公式渲染为图片
BufferedImage image = shape.getImageData().toImage();
ByteArrayOutputStream stream = new ByteArrayOutputStream();
ImageIO.write(image, "PNG", stream);
System.out.println("image: " + Base64.getEncoder().encodeToString(stream.toByteArray()));
Shape newShape = new Shape(document, ShapeType.IMAGE);
newShape.getImageData().setImage(image);
// 替换原 OLE 对象为图片
shape.getParentNode().insertBefore(newShape, shape);
shape.remove();
}
}
@haibojiang 您可能会遇到这样的问题,因为文档中使用的字体在文档转换环境中不可用。要创建准确的文档布局,需要使用字体。如果 Aspose.Words 无法找到文档中使用的字体,就会使用替代字体。这可能会由于字体度量的不同而导致布局差异。您可以实现 IWarningCallback,以便在执行字体替换时获得通知。
以下文章可能对您有用: