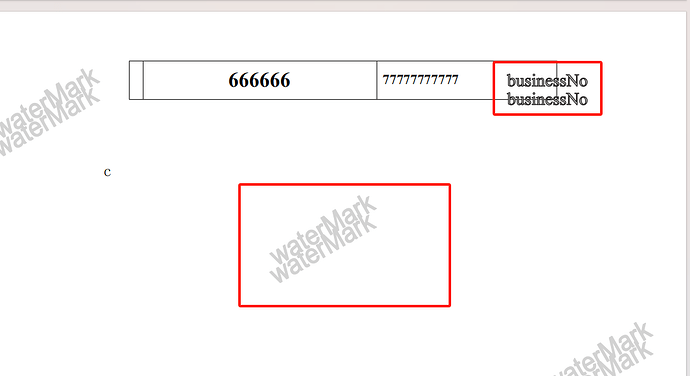
想要达到的效果为:word文档的每一页都能添加水印,同时在每页的右上角添加业务编号。
附件中提供了4页的word文档,同时页眉也分成了4节,其中第3节的页眉是包含内容的,我使用附件中的代码调试后,发现生成的pdf中第3节页眉中的内容消失了。
请问如何调整
hello.docx (44.6 KB)
hello.pdf (1.0 MB)
pdf中第三页页眉中内容不见了
想要达到的效果为:word文档的每一页都能添加水印,同时在每页的右上角添加业务编号。
附件中提供了4页的word文档,同时页眉也分成了4节,其中第3节的页眉是包含内容的,我使用附件中的代码调试后,发现生成的pdf中第3节页眉中的内容消失了。
请问如何调整
hello.docx (44.6 KB)
hello.pdf (1.0 MB)
pdf中第三页页眉中内容不见了
@craspose 在您的文档中,页眉/页脚链接到上一个。 因此,添加标头后,它们将取消链接。 请尝试使用以下代码:
int[] headerTypes = new int[] { HeaderFooterType.HEADER_FIRST, HeaderFooterType.HEADER_PRIMARY, HeaderFooterType.HEADER_EVEN };
int[] headerFooterTypes = new int[] { HeaderFooterType.HEADER_FIRST, HeaderFooterType.HEADER_PRIMARY, HeaderFooterType.HEADER_EVEN, HeaderFooterType.FOOTER_FIRST, HeaderFooterType.FOOTER_PRIMARY, HeaderFooterType.FOOTER_EVEN };
Document doc = new Document("C:\\Temp\\in.docx");
DocumentBuilder builder = new DocumentBuilder(doc);
for (Section s : doc.getSections())
{
// unlink headers/footers from the previous sections
if (s != doc.getFirstSection())
{
Section prevSection = (Section)s.getPreviousSibling();
for (int hfType : headerFooterTypes)
{
// Check whether header/footer of the current section is linked to previous.
// header/footer is linked to previous if it is null or has the appropriate flag set
if (prevSection.getHeadersFooters().getByHeaderFooterType(hfType) != null && (s.getHeadersFooters().getByHeaderFooterType(hfType) == null || s.getHeadersFooters().getByHeaderFooterType(hfType).isLinkedToPrevious()))
{
if (s.getHeadersFooters().getByHeaderFooterType(hfType) != null)
s.getHeadersFooters().getByHeaderFooterType(hfType).remove();
s.getHeadersFooters().add(prevSection.getHeadersFooters().getByHeaderFooterType(hfType).deepClone(true));
}
}
}
// Put some text at right in the header.
builder.moveToSection(doc.getSections().indexOf(s));
for (int headerType : headerTypes)
{
builder.moveToHeaderFooter(headerType);
builder.moveTo(s.getHeadersFooters().getByHeaderFooterType(headerType).getLastParagraph());
builder.getParagraphFormat().setAlignment(ParagraphAlignment.RIGHT);
builder.write("This is some text");
}
}
// Add watermark
doc.getWatermark().setText("Watermark");
doc.save("C:\\Temp\\out.docx");
doc.getWatermark()这个方法不存在呢
您使用的是非常旧的 Aspose.Words 版本,大约 9 年前发布。 请参阅我们的文档以了解如何使用水印:
https://docs.aspose.com/words/java/working-with-watermark/
请尝试像这样修改您的代码:
Document document = new Document("C:\\Temp\\hello.docx");
DocumentBuilder builder = new DocumentBuilder(document);
String warterMark = "waterMark";
String contrNo = "businessNo";
Paragraph watermarkPara = new Paragraph(document);
Random random = new Random();
int lineIndex = 0;
int randomX = random.nextInt(5) * -20 - 80;
for (int y = -20; y < 700; y += 110)
{
int x = lineIndex * 240 + randomX;
lineIndex++;
if (lineIndex > 3)
{
lineIndex = 0;
randomX = random.nextInt(5) * -20 - 80;
}
// 旋转的水印文字
Shape waterTextShape = getWaterMarkTextShape(document, warterMark, x, y);
watermarkPara.appendChild(waterTextShape);
}
// 右上角的水印文字
Shape waterMarkContrNoShape = getWaterMarkContrNoShape(document, contrNo);
watermarkPara.appendChild(waterMarkContrNoShape);
int[] headerTypes = new int[] { HeaderFooterType.HEADER_FIRST, HeaderFooterType.HEADER_PRIMARY, HeaderFooterType.HEADER_EVEN };
int[] headerFooterTypes = new int[] { HeaderFooterType.HEADER_FIRST, HeaderFooterType.HEADER_PRIMARY, HeaderFooterType.HEADER_EVEN, HeaderFooterType.FOOTER_FIRST, HeaderFooterType.FOOTER_PRIMARY, HeaderFooterType.FOOTER_EVEN };
for (Section section : document.getSections())
{
for (int headerType : headerTypes)
{
HeaderFooter hf = section.getHeadersFooters().getByHeaderFooterType(headerType);
if (hf != null)
hf.appendChild(watermarkPara.deepClone(true));
}
if (section != document.getFirstSection())
{
Section prevSection = (Section)section.getPreviousSibling();
for (int hfType : headerFooterTypes)
{
HeaderFooter current = section.getHeadersFooters().getByHeaderFooterType(hfType);
HeaderFooter prev = prevSection.getHeadersFooters().getByHeaderFooterType(hfType);
if (prev != null && (current == null || current.isLinkedToPrevious()))
{
if (current != null)
current.remove();
section.getHeadersFooters().add(prev.deepClone(true));
}
}
}
}
document.save("C:\\Temp\\out.docx");
document.save("C:\\Temp\\out.pdf");
感谢老师,已达到想要的效果
@craspose 出现此问题的原因是文档中的第一部分没有任何标题:
正如您所看到的,第一部分中只有主页脚,因此以下代码对第一部分没有任何影响:
for (int headerType : headerTypes)
{
HeaderFooter hf = section.getHeadersFooters().getByHeaderFooterType(headerType);
if (hf != null)
{
hf.appendChild(watermarkPara.deepClone(true));
}
}